
YOLO (You Only Look Once) là một trong những mô hình nổi tiếng nhất trong Object Detection (phát hiện đối tượng). Khi mới ra mắt, YOLO đã cho thấy một tốc độ vượt trội so với những đối thủ của mình. Tuy sau đó có sự xuất hiện của những đối thủ rất đáng gờm (vừa nhanh, vừa chính xác) như RetinaNet, SSD (Single Shot Detector), YOLO cũng không ngừng phát triển với những biến thể riêng của mình (YOLO 9000, YOLOv3, …).

Hãy cùng tìm hiểu một chút về YOLO và cách áp dụng mô hình này cho bài toán Object Detection với thư viện OpenCV trong bài hôm nay.
Sơ lược về YOLO
Trước khi YOLO được công bố, những mô hình tốt nhất trong Object Detection đều thuộc “họ gia đình” R-CNN (Region Proposals + CNN). Những mô hình này thường bao gồm 2 bước nên có tốc độ không cao (1 bước đề xuất vùng có đối tượng, 1 bước phân loại đối tượng trong vùng được đề xuất).
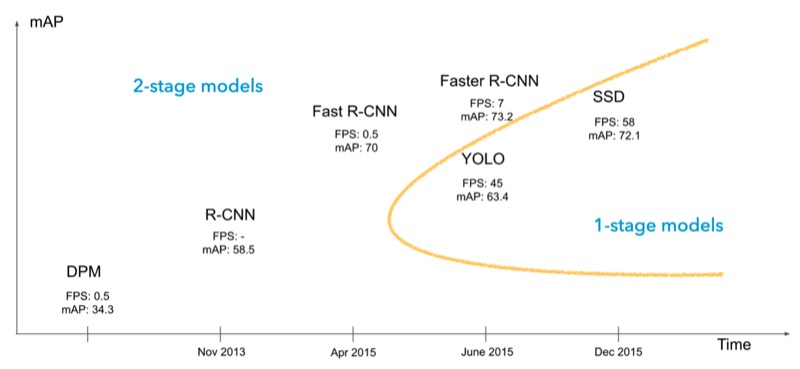
So với họ mô hình R-CNN, YOLO và SSD có tốc độ được cải thiện rất nhiều. Các thuật toán này coi việc phát hiện đối tượng như một bài toán hồi quy, chỉ dùng một mô hình để xác định đồng thời tọa độ đường bao và xác suất của nhóm đối tượng tương ứng. Nếu các bạn để ý, tên của các mô hình này đều nói đến việc chúng chỉ dùng mô hình 1 bước thay vì mô hình 2 bước xuất hiện trước đó (You Only Look Once - Bạn chỉ nhìn một lần và Single Shot Detectors - máy phát hiện chỉ dùng một ảnh).
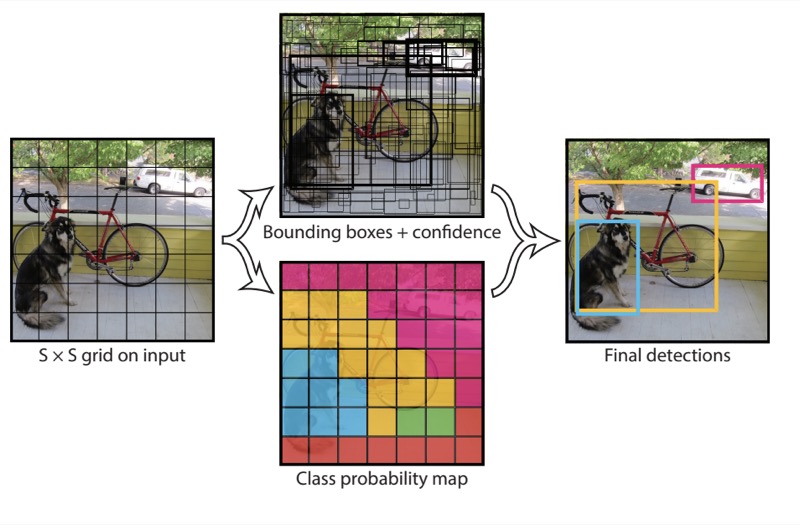
Về cơ bản, YOLO chia ảnh đầu vào thành các ô nhỏ, mô hình sẽ dự đoán xác xuất đối tượng trong các đường bao (bounding-box) xung quanh mỗi ô nhỏ này. Những đường bao có xác xuất cao sẽ được giữ lại và sử dụng cho nhiệm vụ xác định vị trí của đối tượng trong ảnh.
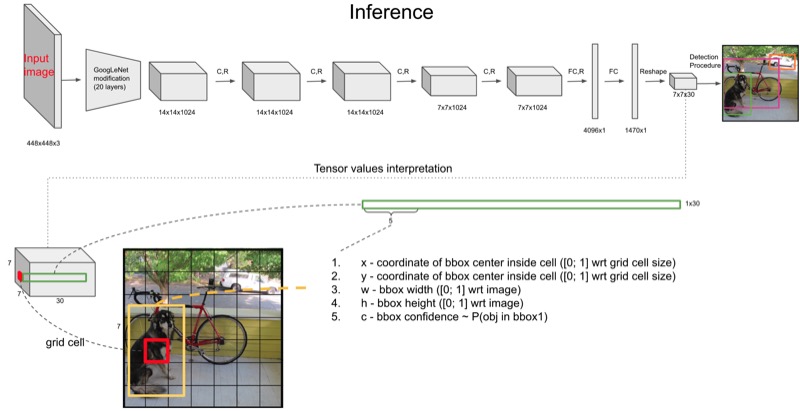
Các phiên bản YOLO
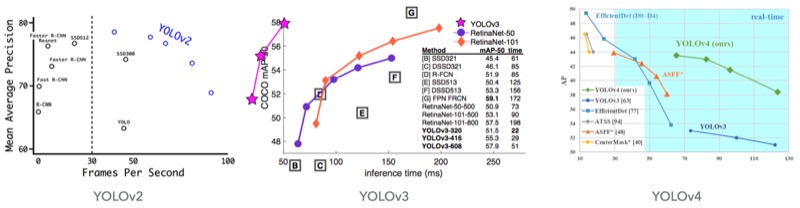
YOLO được giới thiệu vào năm 2015 với khả năng xử lý 45 khung hình trên giây (frames per second - FPS), tốt hơn rất nhiều so với mô hình nhanh nhất thời điểm đó (Faster R-CNN chỉ đạt 7 FPS). Thậm chí, một phiên bản nhỏ của YOLO có thể đạt tốc độ rất ấn tượng với 155 FPS.
Sau đó, có nhiều phiên bản YOLO được ra mắt (4 phiên bản chính thức YOLOv1 - v4, 1 phiên bản YOLOv5 đang được phát triển) và phiên bản nào cũng cho thấy sự cải thiện đáng kể (đặc biệt là về mặt tốc độ) so với các mô hình tốt nhất thời điểm đó.
Có một điều đặc biệt là tác giả của YOLO, Joseph Redmon, đã dừng việc nghiên cứu sau phiên bản YOLOv3 vì lo ngại về việc công nghệ này bị sử dụng sai mục đích. Những phiên bản xuất hiện sau đó thuộc về những tác giả khác như Alexey Bochkovskiy (YOLOv4), Glenn Jocher (YOLOv5).
Mình rất ấn tượng với điều này vì tác giả hoàn toàn có thể nhận thêm tài trợ để nghiên cứu nhưng ông đã không làm điều đó, mình xin trích lại lời chia sẻ của tác giả ở đây:
I stopped doing CV research because I saw the impact my work was having. I loved the work but the military applications and privacy concerns eventually became impossible to ignore.
Thực hành
Trong bài hôm nay, chúng ta sẽ thực hành áp dụng mô hình YOLOv4 (mô hình YOLO chính thức tốt nhất hiện nay) cho bài toán Object Detection. Chúng ta sẽ sử dụng mô hình đã được huấn luyện trên tập dữ liệu COCO (Microsoft Common Objects in Context) với 80 nhóm đối tượng khác nhau:
người
xe đạp, xe ô tô, xe buýt, tàu hoả, máy bay
con chim, con mèo, con chó, con ngựa, con bò
...
Cấu trúc code
Mã nguồn được dùng trong bài hôm nay được lưu tại PandaML Blog GitHub để tiện cho việc tham khảo. Cấu trúc code cụ thể như sau:
.
├── images
│ ├── bus_and_car.jpeg
│ ├── people_and_bicyble.jpeg
│ └── ronaldo_bicycle_kick.jpeg
├── models
│ ├── coco.names
│ ├── yolov4.cfg
│ └── yolov4.weights
├── object_detection.py
└── utils.py
- File
object_detection.pylà file code chính được sử dụng - File
utils.pychứa các hàm được dùng trongobject_detection.py - Thư mục
modelschứa file mô hình đã được huấn luyện - Thư mục
imageschứa các ảnh được dùng để thử nghiệm mô hình
Để áp dụng Object Detection cho một ảnh mới, chúng ta có thể dùng đoạn code dưới đây:
python object_detection.py --image [đường dẫn đến ảnh]
Nội dung code
Trước tiên, chúng ta cần đọc các files mô hình:
1
2
3
4
5
# load model
# (might need to change to absolute path rather than relative path)
weights_path = "models/yolov4.weights"
config_path = "models/yolov4.cfg"
net = cv2.dnn.readNetFromDarknet(config_path, weights_path)
Mô hình chúng ta dùng ở đây được lưu thành 2 files: 1 file lưu thông tin cấu trúc mạng neuron (config) và 1 file lưu thông tin về mức độ liên kết giữa các neuron (weights). Ở đây chúng ta dùng mô hình được xây dựng trên Darknet nên hàm readNetFromDarknet được sử dụng.
Bước tiếp theo là áp dụng mô hình lên ảnh:
1
2
3
4
5
6
# run model
model = cv2.dnn_DetectionModel(net)
model.setInputParams(scale=1 / 255, size=(416, 416), swapRB=True)
class_ids, scores, boxes = model.detect(
image, confThreshold=CONFIDENCE_THRESHOLD, nmsThreshold=NMS_THRESHOLD
)
- Dòng 2: tạo mô hình với hàm
cv2.dnn_DetectionModel - Dòng 3: đặt các tham số liên quan đến tiền xử lý ảnh, trong đó:
scale: tỉ lệ để chuẩn hoá các điểm ảnhsize: độ phân giải ảnh đầu vào của mô hìnhswapRB: tham số quyết định xem có cần phải đổi giữa kênh màu đỏ và xanh lục hay không, do openCV lưu ảnh theo thứ tự BGR mà mô hình được huấn luyện theo ảnh RGB nên tham số cần đặt làTruetrong bài này.
Lưu ý là các mô hình khác nhau có yêu cầu về kích thuớc ảnh đầu vào và bước tiền xử lý khác nhau. Chúng ta cần hiểu rõ các bước này để đặt các tham số sao cho phù hợp.
- Dòng 4 - 6: chạy mô hình Object Detection
confThreshold: đối tượng nào có điểm xác suất cao hơn ngưỡng này mới được giữ lạinmsThreshold: ngưỡng cho thuật toán Non Max Suppression (NMS) được dùng trong YOLO, thuật toán này sẽ lọc bớt các đường bao nhiễu và giữ lại đường tốt nhất cho từng đối tượng.
Đầu ra của bước chạy mô hình gồm 3 thành phần:
class_ids: chứa id của đối tượng được tìm thấyscores: độ chắc chắn của mô hình tương ứng với những đối tượng trênboxes: chứa toạ độ của đường bao
Dựa vào các thông số trên, bước cuối cùng là vẽ đường bao (bounding box) cho các đối tượng được phát hiện trong ảnh:
1
2
3
4
5
for (class_id, score, box) in zip(class_ids, scores, boxes):
label = "%s: %.2f" % (CLASSES[class_id], score)
color = COLORS[class_id]
x1, y1, x2, y2 = yolo_box_to_points(box)
draw_bounding_box_with_label(image, x1, y1, x2, y2, label, color)
- Dòng 4:
yolo_box_to_pointschuyển đổi toạ độ đường bao sang dạng (x1, y1), (x2, y2) để tiện cho việc vẽ hình với OpenCV - Dòng 5:
draw_bounding_box_with_labelvẽ đường bao cùng với tên đối tượng tương ứng
Mã nguồn (source code)
Kết quả
Dưới đây là kết quả khi áp dụng mô hình của chúng ta lên ảnh trong thư mực images, các bạn hãy thử so sánh với mô hình SSD-mobilnet ở bài trước xem sao nhé.
Ảnh đầu tiên mô hình cho kết quả khá tốt với 2 người và chiếc xe đạp được phát hiện đúng, kết quả tương tự với SSD-mobilenet.
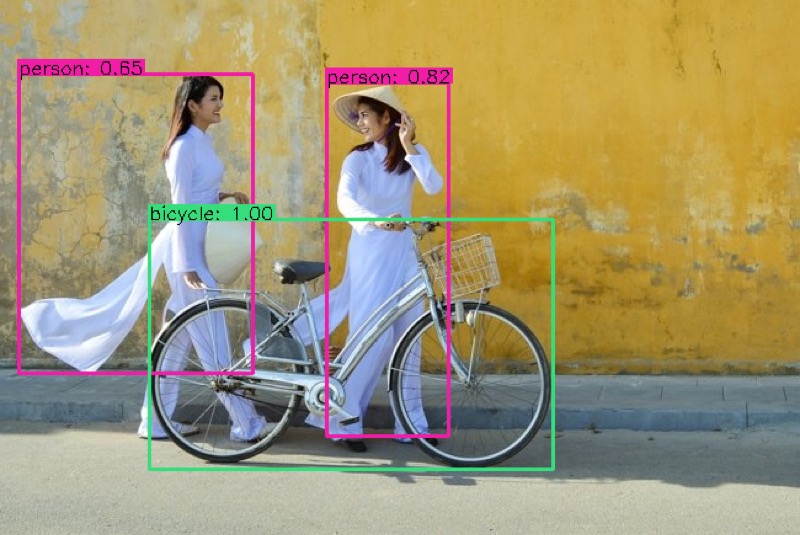
Ảnh thứ hai phát hiện được rất nhiều đối tượng và tương đối chính xác. Lần này YOLOv4 cho kết quả tốt hơn so với mô hình SSD-mobilnet.

Ảnh thứ ba thì YOLOv4 phát hiện đúng các cầu thủ (SSD-mobilenet nhận Ronaldo là con chim) nhưng lại nhận nhầm 1 đối tượng trong nền.

Tạm kết
Bài hôm nay đã giới thiệu đến các bạn phương pháp YOLO trong Object Detection. Sau đó, chúng ta thực hành với mô hình YOLOv4 dựa trên mô đun dnn của thư viện OpenCV và YOLOv4 đã cho thấy độ chính xác rất tốt trên một vài ảnh thử nghiệm.
Vậy còn YOLOv5 thì sao? Liệu phiên bản này có tốt hơn YOLOv4? Tuy chưa có bài báo chính thức về YOLOv5, nhưng mình tin là mô hình này sẽ không thua kém gì các phiên bản tiền nhiệm. Và hy vọng rằng trong tương lai, các mô hình YOLO nói riêng và các mô hình Object Detection nói chung sẽ ngày càng được phát triển, kéo theo những ứng dụng thú vị trong mảng này.

Leave a comment