
Trong bài hôm nay, chúng ta sẽ học cách sử dụng phương pháp kiểm định chéo để đánh giá chất lượng mô hình.
Giới thiệu
Xây dựng mô học máy là một quy trình lặp đi lặp lại với các bước như:
- Lựa chọn đặc trưng
- Lựa chọn mô hình
- Lựa chọn các tham số của mô hình
Và chúng ta đã biết cách đánh giá chất lượng mô hình bằng cách chia dữ liệu làm 2 phần huấn luyện và kiểm định. Tuy nhiên phương pháp này cũng có một số hạn chế nhất định. Tưởng tượng rằng dữ liệu của bạn có 5000 dòng, thông thường một phần 20% dữ liệu được chọn để làm tập kiểm định, tương đương với 1000 dòng dữ liệu. Do đây là một sự lựa chọn ngẫu nhiên, mô hình có thể hoạt động tốt cho 1000 dòng này, nhưng có thể lại không chính xác cho 1000 dòng khác.
Nhìn chung, một tập kiểm định với nhiều dữ liệu sẽ tốt hơn vì giảm được ảnh hưởng ngẫu nhiên nói trên. Nhưng điều này cũng đồng nghĩa với việc tập huấn luyện của chúng ta sẽ nhỏ hơn, và mô hình có thể không tìm ra được quy luật nào rõ ràng nữa.
Kiểm định chéo (cross-validation)
Hạn chế nói trên sẽ được giải quyết với phương pháp kiểm định chéo, chúng ta xây dựng mô hình và đánh giá chất lượng trên nhiều tập dữ liệu nhỏ rồi lấy kết quả trung bình.
Ví dụ, chúng ta có thể chia dữ liêu làm 5 phần (5 folds), mỗi phần chiếm 20% dữ liệu.
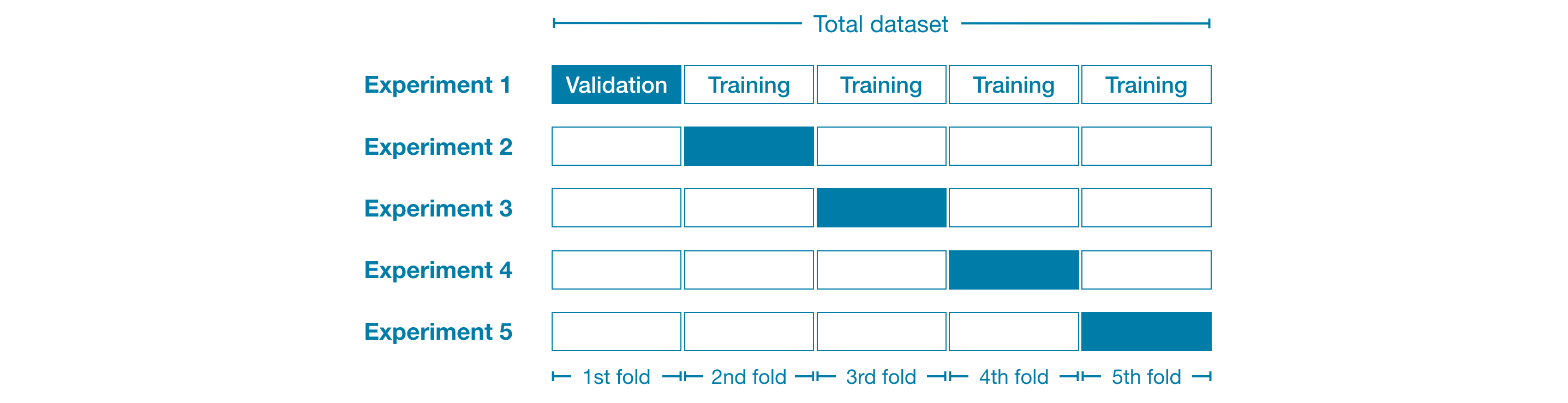
Sau đó chúng ta thử nghiệm mô hình cho trên mỗi phần:
- Thử nghiệm 1: chúng ta dùng phần dữ liệu đầu tiên làm tập kiểm định và dùng tất cả phần còn lại dùng để huấn luyện mô hình. Bước này cho chúng ta đánh giá mô hình cho 20% dữ liệu.
- Thử nghiệm 2: chúng ta dùng phần dữ liệu tiếp theo làm tập kiểm định và dùng tất cả phần còn lại dùng để huấn luyện mô hình.
- Lặp lại quá trình trên cho tất các các phần và chúng ta sẽ có 100% dữ liệu được dùng để kiểm định. Hay nói cách khác, chúng ta đã đánh giá mô hình trên toàn bộ dữ liệu (mặc dù chúng ta không dùng tất cả cùng một lúc).
Khi nào nên dùng kiểm định chéo
Kiểm định chéo cho chúng ta một đánh giá đáng tin cậy hơn về chất lượng mô hình, điều này đặc biệt quan trọng khi chúng ta cần thử nghiệm nhiều mô hình và tham số khác nhau. Tuy nhiên, phương pháp này cũng mất nhiều thời gian hơn do cần thực hiện việc huấn luyện mô hình nhiều lần.
Vậy khi nào thì nên dùng kiểm định chéo? Trên thực tế:
- Với dữ liệu nhỏ, khi thời gian huấn luyện mô hình không quá lớn, chúng ta nên dùng kiểm định chéo.
- Với dữ liệu lớn, tập kiểm định có thể đã có đủ dữ liệu (để giảm bớt ảnh hưởng của việc lựa chọn ngẫu nhiên), do đó chúng ta nên dùng phương pháp kiểm định thông thường với một tập kiểm định. Hơn nữa, code của chúng ta sẽ chạy nhanh hơn.
Không có một tiêu chuẩn nhất định về việc dữ liệu nhỏ hay lớn, nhưng nếu mô hình chỉ mất vài phút để huấn luyện, có lẽ sẽ tốt hơn nếu chuyển sang dùng kiểm định chéo.
Hoặc chúng ta có thể chạy kiểm định chéo và kiểm tra sai số cho các phần, nếu sai số gần nhau, một tập kiểm định là đủ.
Thực hành
Bài thực hành hôm nay tiếp tục sử dụng dữ liệu về giá nhà tại Melbourne, Úc. Mô hình của chúng ta sẽ sử dụng các đặc trưng như số phòng và diện tích đất để dự đoán giá nhà.
Trước hết hãy đọc dữ liệu rồi chọn biến mục tiêu y và đặc trưng X.
import pandas as pd
# Đọc dữ liệu
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Lựa chọn một phần nhỏ của các biến đặc trưng
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Chọn biến mục tiêu
y = data.Price
Sau đó, chúng ta tạo một pipeline kết hợp bước thay thế giá trị bị thiếu và mô hình rừng ngẫu nhiên để dự đoán giá nhà. Việc sử dụng pipeline sẽ giúp cho việc kiểm định chéo dễ dàng hơn khá nhiều.
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
my_pipeline = Pipeline(steps=[('preprocessor', SimpleImputer()),
('model', RandomForestRegressor(n_estimators=50, random_state=0))
])
Chúng ta có thể dùng hàm cross_val_score() từ thư viện scikit-learn cho kiểm định chéo.
from sklearn.model_selection import cross_val_score
# Nhân với -1 vì sklearn tính sai số trung bình tuyệt đối âm
scores = -1 * cross_val_score(my_pipeline, X, y,
cv=5,
scoring='neg_mean_absolute_error')
print("MAE scores:\n", scores)
# [301628.7893587 303164.4782723 287298.331666 236061.84754543 260383.45111427]
- Tham số
cv: số phần dữ liệu trong kiểm định chéo. - Tham số
scoring: chỉ số đánh giá, trong trường hợp này chúng ta dùng sai số âm trung bình tuyệt đối (MAE âm). Có nhiều lựa chọn khác từ thư viện scikit-learn, chúng ta có thể tham khảo danh sách ở đây.
Nhiều bạn sẽ hỏi tại sao phải dùng sai số âm mà không dùng sai số thông thường. Điều này là do thư viện scikit-learn sử dụng một quy ước trong đó tất cả các chỉ số đều được định nghĩa sao cho giá trị lớn là tốt nhất. Việc sử dụng sai số âm là để tuân theo quy ước đó, mặc dù chỉ số này gần như không tồn tại ở bất kỳ nơi nào khác.
Thông thường, chúng ta muốn dùng một chỉ số để so sánh các mô hình khác nhau nên chúng ta lấy sai số trung bình của các phần dữ liệu.
print("Average MAE score (across experiments):")
print(scores.mean())
# 277707.3795913405
Kết luận
Kiểm định chéo là phương pháp đáng tin cậy hơn cho việc đánh giá chất lượng mô hình. Không những thế, với phương pháp này code của chúng ta cũng gọn gàng hơn khi không cần bước chia dữ liệu thành tập huấn luyện và kiểm định riêng biệt.
Với dữ liệu nhỏ, chúng ta chắc chắn nên dùng kiểm định chéo. Còn với dữ liệu lớn hơn, tuỳ từng trường hợp mà chúng ta chọn kiểm định chéo hoặc kiểm định thông thường.
Trong cuộc thi dự đoán giá nhà cho người dùng của Kaggle Learn, các bạn thấy có nên dùng kiểm định chéo không?
Bạn có thể dùng Kaggle notebook ở đây để thực hành. Happy learning!

Leave a comment