
Trong bài hôm nay, chúng ta sẽ tìm hiểu về vấn đề rò rỉ dữ liệu và một số cách để tránh gặp phải vấn đề này trong thực tiễn. Nếu không biết cách xử lý, rò rỉ dữ liệu sẽ âm thầm phá hỏng mô hình của chúng ta. Do đó, đây là một khái niệm quan trọng cho cần được lưu ý.
Giới thiệu
Rò rỉ dữ liệu (data leakage, hay leakage) xảy ra khi tập dữ liệu huấn luyện chứa thông tin nào đó về mục tiêu cần dự đoán, nhưng thông tin tương tự không tồn tại khi triển khai thực tế. Điều này có thể dẫn đến độ chính xác cao trên tập huấn luyện (và thậm chí cả tập kiểm định), nhưng lại hoạt động không tốt khi triển khai thực tế.
Nói cách khác, rò rỉ dữ liệu khiến cho mô hình trông có vẻ chính xác nhưng thực ra không phải như vậy.
Có 2 dạng rò rỉ dữ liệu: target leakage (rò rỉ mục tiêu?) và train-test contamination (rò rỉ huấn luyện-kiểm định?).
Target leakage
Target leakage xảy ra khi mô hình sử dụng dữ liệu khong có sẵn tại thời điểm thực hiện các dự đoán.
Hãy thử tìm hiểu bài toán dự đoán ai mắc bệnh viêm phổi dưới đây:
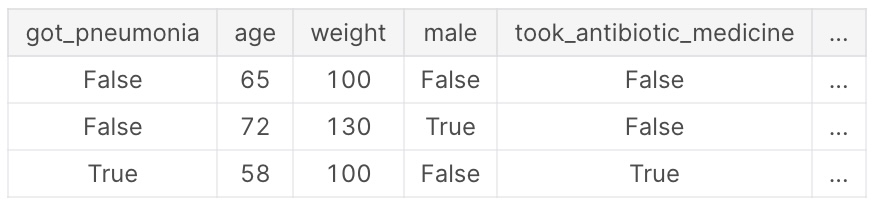
Chúng ta có thể thấy mối liên hệ chặt chẽ giữa việc đặc trưng took_antibiotic_medicine (uống thuốc kháng sinh) và biến mục tiêu got_pneumonia (mắc viêm phổi). Mô hình học máy có thể tìm ra mối liên hệ này và dự đoán ai không uống thuốc thì không mắc bệnh viêm phổi. Và mô hình sẽ có độ chính xác rất cao trên tập kiểm định (validation).
Tuy nhiên, lưu ý rằng những ai được chẩn đoán viêm phổi thì sau đó mới uống thuốc kháng sinh. Do đó, khi chúng ta sử dụng mô hình để dự đoán, chúng ta hoàn toàn không có thông tin về việc uống thuốc, mô hình sẽ không còn chính xác nữa.
Để tránh target leakage, chúng ta cần loại bỏ những biến số / đặc trưng được cập nhật sau khi giá trị mục tiêu được xác định.
Train-test contamination
Một dạng rò rỉ khác xảy ra khi chúng ta không cẩn thận sử dụng thông tin từ tập kiểm định trên tập huấn luyện.
Hãy nhớ rằng, tập kiểm định được sử dụng để đánh giá chất lượng mô hình trên dữ liệu hoàn toàn mới. Chúng ta có thể vô tình làm điều này nếu tập kiểm định ảnh hưởng đến quá trình tiền xử lý dữ liệu trên tập huấn luyện.
Hãy tưởng tượng bạn xử lý dữ liệu (như thay thế dữ liệu bị thiếu) trước khi chia dữ liệu thành tập huấn luyện và kiểm định. Mô hình của bạn có thể đạt được sai số nhỏ trên tập kiểm định, nhưng lại thiếu chính xác khi dự đoán trong thực tế. Vấn đề nằm ở chỗ bạn đã dùng thông tin từ tập kiểm định trong quá trình xử lý dữ liệu (như sử dụng giá trị trung bình để điền vào giá trị bị thiếu), điều mà chúng ta không có được trên một tập dữ liệu mới.
Để tránh rò rỉ dữ liệu, chúng ta cần để riêng tập kiểm định sang một bên và không động vào nó trong các bước xử lý dữ liệu và huấn luyện mô hình. Tất nhiên chúng ta cần áp dụng các bước tương tự trên tập kiểm định. Và điều này sẽ dễ hơn nếu chúng ta dùng scikit-learn pipelines.

Thực hành
Trong ví dụ hôm nay, chúng ta sẽ học cách xác định và loại bỏ target leakage.
Bài toán của chúng ta là dự đoán khả năng được duyệt của đơn đăng ký thẻ tín dụng. Hãy bắt đầu bằng việc đọc dữ liệu, đặt biến mục tiêu và các đặc trưng.
import pandas as pd
# Đọc dữ liệu
data = pd.read_csv('../input/aer-credit-card-data/AER_credit_card_data.csv',
true_values = ['yes'], false_values = ['no'])
# Chọn biến mục tiêu
y = data.card
# Chọn các đặc trưng
X = data.drop(['card'], axis=1)
print("Number of rows in the dataset:", X.shape[0])
X.head()
# 1319

Dữ liệu này tương đối nhỏ, chúng ta sẽ dùng kiểm định chéo để đánh giá chất lượng mô hình.
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# Chúng ta không cần pipelins do chỉ có một bược khởi tạo mô hình
# nhưng vẫn dùng pipelines vẫn là cách tốt nhất
my_pipeline = make_pipeline(RandomForestClassifier(n_estimators=100))
cv_scores = cross_val_score(my_pipeline, X, y,
cv=5,
scoring='accuracy')
print("Cross-validation accuracy: %f" % cv_scores.mean())
# 0.981052
Rất khó để một mô hình có thể đạt được độ chính xác lên tới 98%. Nó có thể xảy ra, nhưng rất hiếm khi xảy ra trong thực tế, do đó chúng ta cần tìm hiểu về dữ liệu kĩ càng hơn để tránh target leakage.
Kiểm tra lại các đặc trưng được sử dụng, có một vài trong số đó có vẻ đáng nghi. Ví dụ như expenditure là số tiền chi tiêu hàng tháng, nên nhớ rằng chi tiêu chỉ phát sinh SAU khi thẻ được cấp, có lẽ chúng ta không nên dùng nó để huấn luyện mô hình.
Hãy thử kiểm tra một chút:
expenditures_cardholders = X.expenditure[y]
expenditures_noncardholders = X.expenditure[~y]
print('Fraction of those who did not receive a card and had no expenditures: %.2f' \
%((expenditures_noncardholders == 0).mean()))
print('Fraction of those who received a card and had no expenditures: %.2f' \
%(( expenditures_cardholders == 0).mean()))
# Fraction of those who did not receive a card and had no expenditures: 1.00
# Fraction of those who received a card and had no expenditures: 0.02
Chúng ta có thể thấy tất cả những người không có thẻ tín dụng thì không phát sinh chi tiêu, trong khi chỉ 2% những người có thẻ là không chi tiêu gì. Do đó, việc mô hình có độ chính xác cao rất có khả năng là do có target leakage khi sử dụng đặc trưng expenditures.
Bên cạnh đó, một số đặc trưng khác cũng đáng nghi:
shaređược tính từexpenditures, nên được loại bỏactivevàmajorcards: có mối liên hệ không rõ ràng với thẻ tin dụng đang đăng kí, nhưng tốt nhất là nên loại bỏ nếu chúng ta còn nghi ngờ
# Loại bỏ các đặc trưng dễ dẫn đến leakage
potential_leaks = ['expenditure', 'share', 'active', 'majorcards']
X2 = X.drop(potential_leaks, axis=1)
# Đánh giá mô hình
cv_scores = cross_val_score(my_pipeline, X2, y,
cv=5,
scoring='accuracy')
print("Cross-val accuracy: %f" % cv_scores.mean())
# 0.830919
Tuy độ chính xác của mô hình giảm xuống, nhưng có lẽ mô hình này sẽ đáng tin cậy hơn nhiều so với mô hình với độ chính xác 98% ở trên.
Kết luận
Rò rỉ dữ liệu có thể là một sai lầm rất nghiêm trọng (đáng giá tới hàng triệu đô) trong nhiều ứng dụng khoa học dữ liệu. Việc phân chia cẩn thận giữa tập dữ liệu huấn luyện và kiểm định có thể phòng ngừa train-test contamination, và việc sử dụng pipelines có thể hỗ trợ việc này tương đối dễ dàng. Tương tự, sự kết hợp giữa sự kiến thức, kinh nghiệm và cẩn thận dữ liệu có thể giúp chúng ta tránh được target leakage.
Rò rỉ dữ liệu là một khái niệm mới và tương đối trừu tượng. Bạn có thể thực hành với Kaggle notebook ở đây để hiểu rõ hơn một chút. Happy learning!
Leave a comment