
Object Detection (phát hiện đối tượng) là một trong những công nghệ trong thị giác máy tính được sử dụng phổ biến nhất cho đến nay. Có thể hiểu Object Detection là bài toán tương tự như nhận diện khuôn mặt (Face Detection) nhưng khái quát hơn vì nó có thể được áp dụng để xác định vị trí của nhiều đối tượng khác nhau, ví dụ như xe đạp, xe máy, ô tô, máy bay, chó, mèo, lợn, gà, …

Hiện nay, khi nhắc đến Object Detection dựa trên Deep Learning, khả năng cao là bạn sẽ bắt gặp một trong những “họ” phương pháp dưới đây:
- R-CNN (Region Proposals + CNN)
- SSD (Single Shot Detectors)
- YOLO (You Only Look Once)
Trong đó, các phương pháp R-CNN có độ chính xác cao hơn cả nhưng lại có tốc độ không cao. Còn SSD và YOLO thì ưu tiên tốc độ nên chạy nhanh hơn rất nhiều. Do đó, SSD và YOLO có thể được áp dụng rất rộng rãi, đặc biệt là cho những thiết bị có sức mạnh tính toán hạn chế.
Bài hôm nay sẽ giới thiệu đến các bạn về phương pháp SSD và cách áp dụng một mô hình thuộc “họ” phương pháp này cho bài toán Object Detection.
Sơ lược về SSD
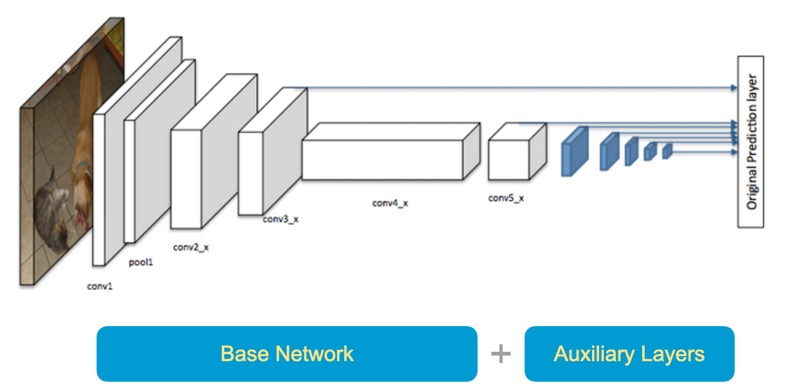
Phương pháp SSD bao gồm 2 thành phần: một mô hình mạng cơ sở (Base Network) và các lớp neuron phụ trợ (Auxiliary Layers). Trong đó, mạng cơ sở có nhiệm vụ trích xuất đặc trưng ảnh, sau đó các đặc trưng này được sử dụng bởi các lớp neuron phụ trợ để dự đoán vị trí của các đối tượng trong ảnh.
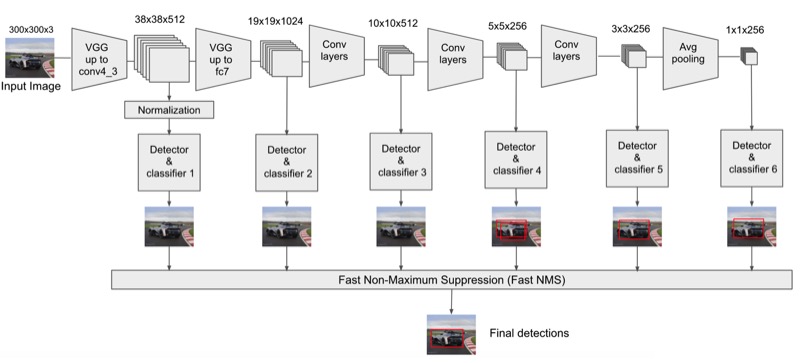
Mạng cơ sở thường là một mô hình phân loại ảnh đã được huấn luyện sẵn, ví dụ như mô hình SSD đầu tiên đã sử dụng mạng VGG, một trong những cấu trúc mạng neuron tốt nhất tại thời điểm đó. Điều thú vị là chúng ta có thể sử dụng cấu trúc mạng bất kì đề làm mạng cơ sở, miễn là cấu trúc đó hoạt động tốt cho “nhiệm vụ” phân loại ảnh. Hiện nay có rất nhiều mô hình được phát triển với độ chính xác cao như ResNet, Inception, Xception, … đây đều là các “ứng viên ưu tú” để làm mạng cơ sở trong phương pháp SSD.
Mô hình SSD với MobileNet
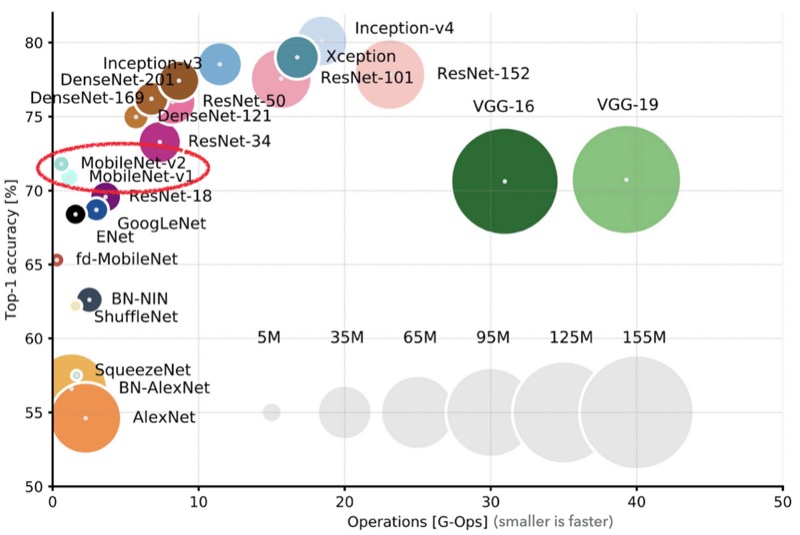
MobileNet là mô hình phân loại ảnh được ra mắt vào năm 2017 bởi nhóm nghiên cứu từ Google. Đây là được thiết kế dành riêng cho các thiết bị với không gian lưu trữ và khả năng tính toán không quá cao. MobileNet có độ chính xác ngang ngửa với VGG nhưng lại có kích thước nhỏ hơn khoảng 20 lần (20 MB so với 500 MB). Do đó, khi dùng MobiletNet làm mô hình cơ sở trong SSD, chúng ta có một mô hình Object Detection vừa nhỏ gọn vừa chính xác.
Thực hành
Trong bài hôm nay, chúng ta sẽ thực hành áp dụng mô hình MobiletNet-SSD cho bài toán Object Detection. Chúng ta sẽ sử dụng mô hình huấn luyện sẵn có khả năng phát hiện 20 nhóm đối tượng khác nhau:
người
bàn, chai, ghế, sofa, chậu cây, màn hình TV
con chim, con chó, con bò, con cừu, con mèo, con ngựa
thuyền, xe buýt, xe lửa, xe máy, xe đạp, ô tô, máy bay
Cấu trúc code
Mã nguồn được dùng trong bài hôm nay được lưu tại PandaML Blog GitHub để tiện cho việc tham khảo. Cấu trúc code cụ thể như sau:
.
├── images
│ ├── bus_and_car.jpeg
│ ├── people_and_bicyble.jpeg
│ └── ronaldo_bicycle_kick.jpeg
├── models
│ ├── MobileNetSSD_deploy.caffemodel
│ └── MobileNetSSD_deploy.prototxt.txt
├── object_detection.py
└── utils.py
- File
object_detection.pylà file code chính được sử dụng - File
utils.pychứa các hàm được dùng trongobject_detection.py - Thư mục
modelschứa file mô hình đã được huấn luyện - Thư mục
imageschứa các ảnh được dùng để thử nghiệm mô hình
Để áp dụng Object Detection cho một ảnh mới, chúng ta có thể dùng đoạn code dưới đây:
python object_detection.py --image [đường dẫn đến ảnh]
Nội dung code
Trước tiên, chúng ta cần đọc các files mô hình:
# load model
weights_path = "models/MobileNetSSD_deploy.caffemodel"
config_path = "models/MobileNetSSD_deploy.prototxt.txt"
net = cv2.dnn.readNetFromCaffe(config_path, weights_path)
Mô hình chúng ta dùng ở đây được lưu thành 2 files: 1 file lưu thông tin cấu trúc mạng neuron (config) và 1 file lưu thông tin về mức độ liên kết giữa các neuron (weights). Ở đây chúng ta dùng mô hình được xây dựng trên Caffe nên hàm readNetFromCaffe được sử dụng.
Bước tiếp theo là áp dụng mô hình lên ảnh:
# run model
blob = cv2.dnn.blobFromImage(resized_image, scalefactor=0.007843, size=input_size, mean=127.5)
net.setInput(blob)
detections = net.forward()
Lưu ý là các mô hình khác nhau có yêu cầu về kích thuớc ảnh đầu vào và bước tiền xử lý khác nhau. Ở đây, hàm cv2.dnn.blobFromImage nhận ảnh đầu vào có cỡ input_size = (300, 300) và sau đó chuẩn hoá ảnh với công thức (pixel_value - mean) * scalefactor, trong đó mean = 127.5 và scalefactor= 1 / 127.5 ~ 0.007843.
Bước cuối cùng là vẽ đường bao (bounding box) cho các đối tượng được phát hiện trong ảnh:
1
2
3
4
5
6
7
8
9
10
11
12
# plot bounding-box
for i in range(detections.shape[2]):
detection = detections[0, 0, i]
confidence = detection[2]
# only keep strong detections
if confidence > CONFIDENCE:
idx = int(detection[1]) # class index
x1, y1, x2, y2 = dnn_detection_to_points(detection, width, height)
label = "%s: %.2f" % (CLASSES[idx], confidence)
color = COLORS[idx]
draw_bounding_box_with_label(image, x1, y1, x2, y2, label=label, color=color)
- Dòng 6: giữ lại những khuôn mặt có độ tin cậy cao
- Dòng 8: hàm
dnn_detection_to_pointschuyển đổi toạ độ của mô hình sang dạng (x1, y1), (x2, y2) để tiện lợi hơn cho việc vẽ hình - Dòng 10 - 12: hàm
draw_bounding_box_with_labelvẽ đường bao của từng đối tượng kèm theo độ tin cậy của mô hình
Mã nguồn (source code)
Kết quả
Dưới đây là kết quả khi áp dụng mô hình của chúng ta lên ảnh trong thư mực images:
Ảnh đầu tiên mô hình cho kết quả khá tốt với 2 người và chiếc xe đạp được phát hiện đúng.

Ảnh thứ hai mô hình nhận nhầm 1 chiếc xe buýt là xe ô tô, có lẽ là do chiếc xe buýt này ở phía xa nên trong ảnh có kích cỡ nhở tương đương với xe ô tô.

Ảnh thứ ba rất thú vị, mô hình nhận nhầm Ronaldo đang thực hiện cú sút xe đạp chổng ngược là con chim, mình thì nghĩ bay như chim thế thì cũng có thể thông cảm cho mô hình này.

Tạm kết
Bài hôm nay đã giới thiệu đến các bạn phương pháp SSD trong Object Detection. Sau đó, chúng ta thực hành với mô hình SSD-Mobilenet dựa trên thư viện OpenCV. Tuy không phải là mô hình có độ chính xác tốt nhất, SSD-MobileNet lại rất phù hợp với những ứng dụng cần tốc độ cao.
Trong những bài tiếp theo, mình sẽ tìm hiểu về những phương pháp khác cho bài toán Object Detection. Các bạn có kinh nghiệm gì thú vị thì hia sẻ để mọi người cùng tham khảo với nhé.

Leave a comment