
Trong bài hôm nay, chúng ta sẽ học cách phát triển và tối ưu mô hình học máy với gradient boosting, phương pháp đã thống trị rất nhiều cuộc thi học máy trên Kaggle.
Giới thiệu
Trong khoá học này, chúng ta phần lớn đã sử dụng mô hình rừng ngẫu nhiên (random forest), một mô hình sử dụng dự đoán trung bình của nhiều cây quyết định (decision tree) riêng lẻ. Phương pháp này được gọi chung là phương pháp tập hợp (ensemble method), một kỹ thuật để kỹ thuật kết hợp nhiều mô hình dự đoán khác nhau để tạo ra một mô hình mạnh mẽ hơn.
Rừng ngẫu nhiên thuộc phương pháp tập hợp Bagging, sử dụng nhiều mô hình độc lập khác nhau. Bài hôm nay, chúng ta sẽ làm quen với một dạng tập hợp khác được gọi là Boosting.
Gradient Boosting
Gradient Boosting cũng kết hợp nhiều mô hình, nhưng các mô hình được xây dựng lần lượt phụ thuộc vào nhau chứ không hoàn toàn độc lập như Bagging.
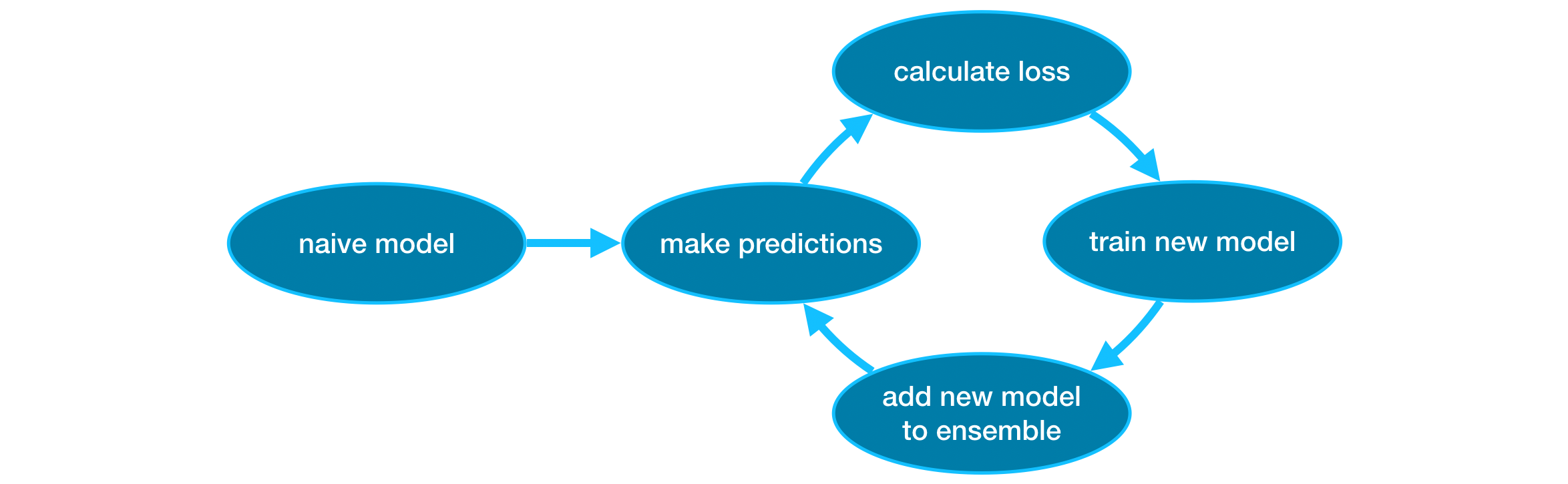
Ban đầu, tập hợp mô hình (ensemble) được khởi tạo với một mô hình. Đây có thể là một mô hình đơn giản với nhiều dự đoán không chính xác, những mô hình thêm vào sau này sẽ xử lý những phần chưa chính xác này.
Sau đó, chúng ta lặp lại quy trình sau:
- Đầu tiên, dùng tập hợp mô hình hiện tại để thực hiện dự đoán (cộng dồn các dự đoán từ tất cả các mô hình trong tập hợp).
- Những dự đoán này được dùng để tính hàm mất mát (loss function, ví dụ như sai số bình phương trung bình).
- Sau đó, chúng ta dùng hàm mất mát để tìm ra một mô hình mới sẽ được thêm vào tập hợp. Các tham số của mô hình được xác định sao cho sai số được giảm thiểu khi thêm mô hình mới vào tập hợp.
- Lưu ý: Từ gradient trong gradient boosting là do phương pháp này sử dụng gradient descent để xác định các tham số của mô hình mơi.
- Cuối cùng, chúng ta thêm mô hình này vào tập hợp của chúng ta.
Thực hành
Bài thực hành hôm nay tiếp tục sử dụng dữ liệu về giá nhà tại Melbourne, Úc. Mô hình của chúng ta sẽ sử dụng các đặc trưng như số phòng và diện tích đất để dự đoán giá nhà.
Hãy bắt đầu bằng việc đọc dữ liệu và chia dữ liệu thành tập huấn luyện và tập điểm định (training & validation data): X_train, X_valid, y_train, y_valid.
import pandas as pd
# Đọc dữ liệu
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Lựa chọn một phần nhỏ của các biến đặc trưng
cols_to_use = ['Rooms', 'Distance', 'Landsize', 'BuildingArea', 'YearBuilt']
X = data[cols_to_use]
# Chọn biến mục tiêu
y = data.Price
# Chia dữ liệu thành tập huấn luyện và kiểm định
X_train, X_valid, y_train, y_valid = train_test_split(X, y)
Scikit-learn API
Tronb ví dụ hôm nay, chúng ta sẽ dùng thử viện Xgboost, viết tắt cho extreme gradient boosting, một mô hình trong gia đình gradient boosting với những tính năng mới tối ưu cho độ chính xác và tốc độ. (Scikit-learn cũng có một phiên bản của gradient boosting nhưng XGboost có một số ưu điểm riêng về mặt kỹ thuật).
Tiếp theo, chúng ta sẽ sử dụng XGBRegressor với cách sử dụng tương tự như các mô hình scikit-learn. XGBregressor cũng có rất nhiều tham số có thể được tinh chỉnh - chúng ta sẽ được thử nghiệm sớm ở mục tiếp theo.
from xgboost import XGBRegressor
my_model = XGBRegressor()
my_model.fit(X_train, y_train)
Sau đó, chúng ta thực hiện dự đoán và đánh giá chất lượng mô hình.
from sklearn.metrics import mean_absolute_error
predictions = my_model.predict(X_valid)
print("Mean Absolute Error: " + str(mean_absolute_error(predictions, y_valid)))
# 241041.5160392121
Tinh chỉnh tham số
XGboost có một vài tham số có thể ảnh hưởng lớn đến độ chính xác và tốc độ huấn luyện. Tiêu biểu như:
n_estimators
n_estimators: số lượng mô hình có trong tập hợp (ensemble).
- Giá trị nhỏ là nguyên nhân của underfiting, dẫn đến sự thiếu chính xác trên cả tập huấn luyện và đánh giá.
- Giá trị lớn là nguyên nhân của overfititng, có thể rất chính xác trên tập huấn luyện nhưng lại thiếu chính xác trên tập đánh giá.
Giá trị n_estimators thương rơi vào khoảng 100 - 1000, nhưng cũng còn tuỳ thuộc vào giá trị learning_rate dưới đây.
Dưới đây là ví dụ khởi tạo mô hình với 500 mô hình nhỏ.
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train)
early_stopping_rounds
early_stopping_rounds cho chúng ta một cách để tìm giá trị lý tưởng cho n_estimator. Với tham số có giá trị là 5, mô hình sẽ dừng việc tìm thêm mô hình mới khi điểm số trên tập kiểm định không được cải thiện sau 5 lượt liên tục. Do đó, thông thường chúng ta nên đặt giá trị lớn cho n_estimators và dùng early_stopping_rounds để tìm giá trị hợp lý nhất cho n_estimators.
Khi dùng early_stopping_rounds, chúng ta cần một phần dữ liệu để đánh giá mô hình trên tập kiểm định. Điều này có thể thực hiện thông qua tham số eval_set.
Chúng ta có thể thêm early_stopping_rounds như sau:
my_model = XGBRegressor(n_estimators=500)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
learning_rate
Thay vì lấy cộng tất cả dự đoán của các mô hình thành phần, chúng ta có thể thêm vào một trọng số nhỏ cho các mô hình này trước khi lấy tổng (trọng số này còn được gọi là learning_rate).
Với learning_rate nhỏ, mỗi mô hình thành phần sẽ có đóng góp nhỏ hơn nên chúng ta có thể có nhiều mô hình (n_estimators lớn) mà không bị overfitting. Trên thực tế, learning_rate nhỏ và n_estimators lớn thường cho kết quả với độ chính xác cao hơn (mặc dù cần nhiều thời gian để huấn luyện hơn).
Giá trị mặc định của learning_rate là 0.1, chúng ta có thể điều chỉnh như sau
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
n_jobs
Tham số n_jobs cho phép chúng ta cài đặt số nhân CPU được dùng cho quá trình huấn luyện mô hình. Tuy dùng nhiều nhân CPU không có nhiều hiệu quả cho tập dữ liệu nhỏ, nó lại cải thiện tốc độ đáng kể trên các tập dữ liệu lớn.
my_model = XGBRegressor(n_estimators=1000, learning_rate=0.05, n_jobs=4)
my_model.fit(X_train, y_train,
early_stopping_rounds=5,
eval_set=[(X_valid, y_valid)],
verbose=False)
Kết luận
Bài hôm nay giới thiệu đến các bạn mô hình XGBoost, một trong những mô hình học máy hàng đầu dành cho dữ liệu dạng bảng. Nếu được tinh chỉnh cẩn thận, mô hình XGBoost sẽ có độ chính xác rất cao.
Còn chờ gì nữa, các bạn hãy thử XGBoost với cuộc thi dự đoán giá nhà cho người dùng của Kaggle Learn.
Bạn có thể dùng Kaggle notebook ở đây để thực hành. Happy learning!

Leave a comment