
Trong bài hôm nay, chúng ta sẽ học cách xây dựng mô hình học máy thông qua pipelines (chuỗi quy trình?).
Giới thiệu
Pipelines là một cách đơn giản để kết hợp các bước trong quá trình xây dựng mô hình học máy (thu thập, xử lý dữ liệu, chia dữ liệu, chọn mô hình, huấn luyện mô hình, …), điều này giúp cho chúng ta có thể sử dụng tất cả các bước này một cách dễ dàng hơn.
Nhiều nhà khoa học dữ liệu phát triển mô hình mà không dùng tới pipelines, nhưng phải nói rằng pipelines có những lợi thế nhất định:
- Code gọn gàng hơn: với pipelines, chúng ta không cần phải kiểm tra liên tục dữ liệu của tập huấn luyện và kiểm định qua từng bước.
- Ít lỗi: với pipelines, chúng ta sẽ không “tình cờ quên” một bước nào trong việc xây dựng mô hình.
- Dễ triển khai: trên thực tế, việc đi từ mô hình mẫu (prototype) đến việc triển khai diện rộng tương đối khó khăn. Pipelines sẽ giúp được phần nào do các bước được “đóng gói” cùng với nhau.
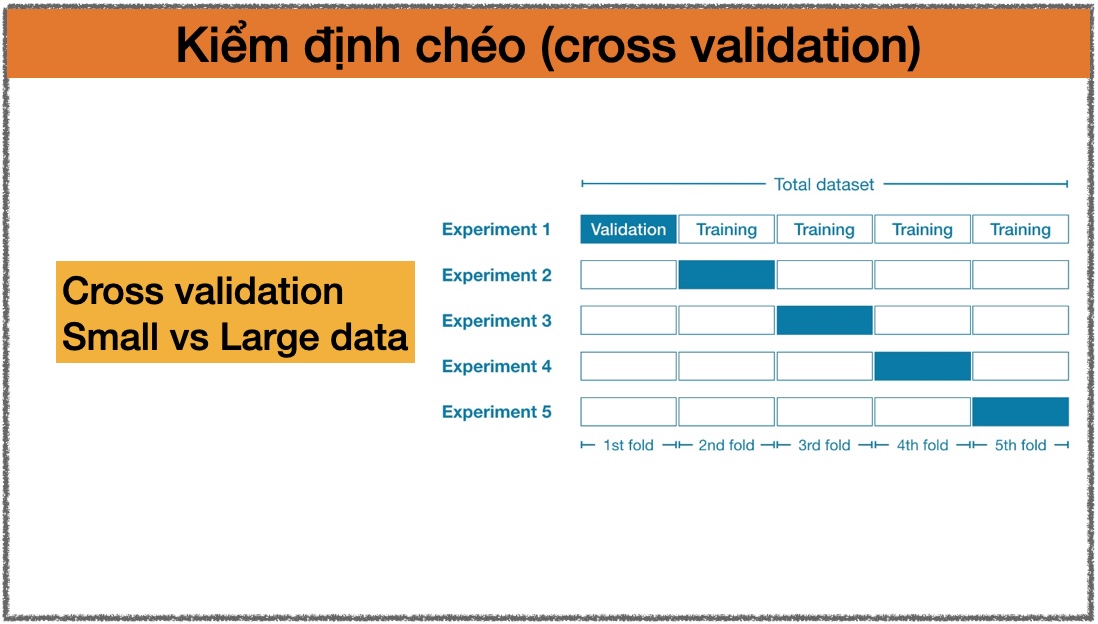
- Nhiều lựa chọn để đánh giá chất lượng mô hình: chúng ta sẽ tìm hiểu một ví dụ trong bài tiếp theo về kiểm định chéo (cross-validation).
Thực hành
Bài thực hành hôm nay sử dụng dữ liệu về giá nhà tại Melbourne, Úc. Mô hình của chúng ta sẽ sử dụng các đặc trưng như số phòng và diện tích đất để dự đoán giá nhà.
Hãy bắt đầu bằng việc đọc dữ liệu và chia dữ liệu thành tập huấn luyện và tập điểm định (training & validation data): X_train, X_valid, y_train, y_valid.
import pandas as pd
from sklearn.model_selection import train_test_split
# Đọc dữ liệu
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Chọn biến mục tiêu và các đặc trưng
y = data.Price
X = data.drop(['Price'], axis=1)
# Chia dữ liêu làm tập huấn luyện và kiểm định
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
# Chọn các biến phân loại với ít nhóm (low cardinality)
categorical_cols = [
cname for cname in X_train_full.columns
if X_train_full[cname].nunique() < 10
and X_train_full[cname].dtype == "object"
]
# Chọn các biến số học
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
# Chỉ giữ các biến đã được chọn
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
Sau đó, chúng ta xây dựng một pipelines qua 3 bước:
Bước 1: Định nghĩa tiền xử lý dữ liệu
Ở ví dụ này, chúng ta dùng ColumnTransformer để liên kết các bước tiền xử lý dữ liệu. Code dưới đây sẽ thực hiện:
- Thay thế giá trị bị thiếu cho các biến số học
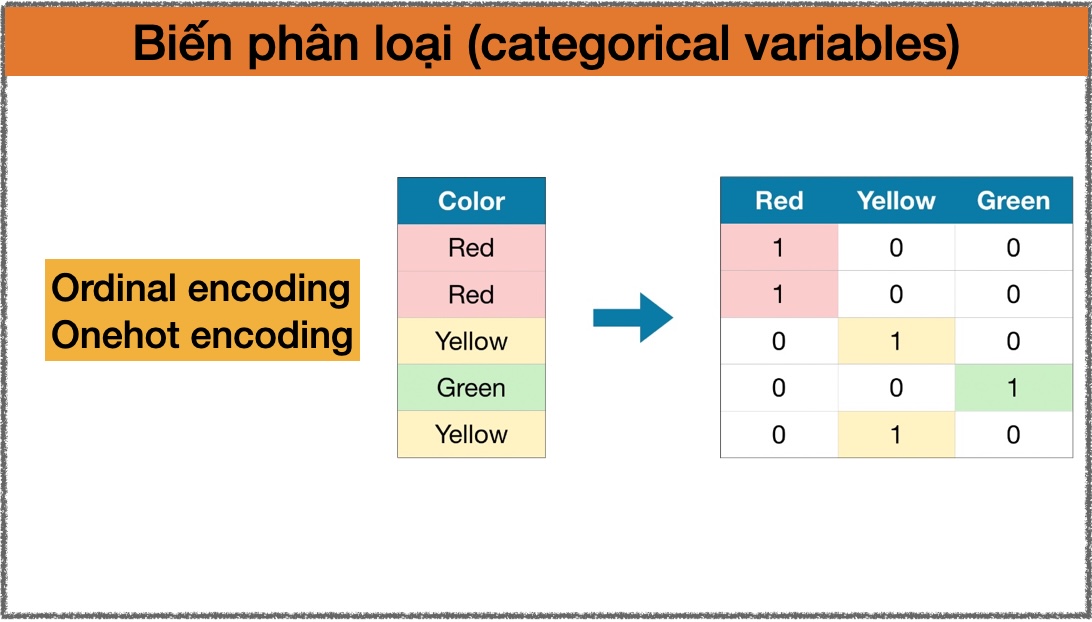
- Áp dụng mã hoá one-hot cho các biến phân loại
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# Tiền xử lý cho dữ liệu số học
numerical_transformer = SimpleImputer(strategy='constant')
# Tiền xử lý cho dữ liệu phân loại
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Kết hợp 2 bước trên
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])
Bước 2: Định nghĩa mô hình
Sau đó, chúng ta khởi tạo một mô hình học máy. Hãy dùng mô hình cây ngẫu nhiên quen thuộc với RandomForestRegressor.
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=100, random_state=0)
Bước 3: Khởi tạo và đánh giá pipelines
Cuối cùng, chúng ta dùng Pipeline để kết hợp bước tiền xử lý dữ liệu với việc huấn luyện mô hình. Có vài điều chúng ta cần lưu ý:
- Với pipeline, chúng ta xử lý dữ liệu huấn luyện và huấn luyện mô hình chỉ với một bước thay vì thực hiện các bước riêng biệt
- Với pieline, chúng ta chỉ cần cung cấp dữ liệu chưa xử lý
X_validđể thực hiện dữ đoán, pipeline sẽ tự động xử lý và chuyển đổi dữ liệu cần thiết.
from sklearn.metrics import mean_absolute_error
# Liên kết bước tiền xử lý dữ liệu và xây dựng mô hình
my_pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)
])
# Xử lý dữ liệu và huấn luyện mô hình với tập huấn luyện
my_pipeline.fit(X_train, y_train)
# Xử lý dữ liệu cho tập kiểm định và thực hiện dự đoán
preds = my_pipeline.predict(X_valid)
# Đánh giá sai số của mô hình
score = mean_absolute_error(y_valid, preds)
print('MAE:', score)
# 160679.18917034855
Kết luận
Bài hôm nay giới thiệu đến các bạn cách dùng pipelines để liên kết các bước xây dựng mô hình học máy với nhau.
Các bạn hãy thử áp dụng cho cuộc thi dự đoán giá nhà cho người dùng của Kaggle Learn và xem piplines có giúp bạn code gọn gàng và ít lỗi hơn không nhé.
Bạn có thể dùng Kaggle notebook ở đây để thực hành. Happy learning!

Leave a comment