
Khi làm việc trong Object Detection, đã bao giờ bạn hí hửng tải mô hình đã được huấn luyện sẵn về rồi phát hiện ra mô hình đó không có đối tượng mà bạn cần? Hoặc độ chính xác của mô hình chưa đủ tốt như mong muốn?
Đối với những trường hợp này thì có lẽ không còn cách nào khác, chúng ta phải huấn luyện mô hình với tập dữ liệu mới. May mắn cho chúng ta là việc huấn luyện mô hình trên tập dữ liệu mới càng ngày càng trở nên dễ dàng.

Hãy cùng tìm hiểu các bước huấn luyện một mô hình Object Detection cho một đối tượng mới, cụ thể là gấu trúc (panda detection) dựa trên YOLOv5 trong bài hôm nay. Mình chọn đối tượng này một phần là mình thích gấu trúc, một phần nữa là mình chưa thấy có mô hình nào có đối tượng này. Hơn nữa, các bước xây dựng mô hình hoàn toàn có thể áp dụng cho bất kỳ một đối tượng nào khác.
Sơ lược về YOLOv5
YOLOv5 là một mô hình Object Detection thuộc họ mô hình YOLO. Nếu các bạn chưa biết thì 3 phiên bản YOLO đầu tiên được phát triển bởi Joseph Redmon. Sau đó, Alexey Bochkovskiy cho ra mắt YOLOv4 với sự cải thiện cả về tốc độ cũng như độ chính xác. Và rồi YOLOv5 được công bố gần đây với những so sánh ban đầu cho thấy độ chính xác tương đương YOLOv4 và có tốc độ nhanh hơn khi thực hiện dự đoán (tuy nhiên vẫn có rất nhiều hoài nghi về độ tin cậy của những so sánh này vì YOLOv5 mới được ra mắt trên GitHub chứ chưa có bài báo chính thức nào cả).
Khác với những phiên bản tiền nhiệm, YOLOv5 được phát triển dựa trên PyTorch thay vì DarkNet. Đây là một điểm cộng không nhỏ cho YOLOv5 vì PyTorch phổ biến hơn rất nhiều, điều này đồng nghĩa với việc sẽ có nhiều tài liệu và hướng dẫn cho chúng ta tham khảo về mô hình này.
Cá nhân mình đánh giá cấu trúc YOLOv5 không có nhiều thay đổi quá lớn nhưng lại được phát triển trên PyTorch và có hướng dẫn rất chi tiết và đầy đủ. Do đó, mình chọn YOLOv5 cho bài thực hành hôm nay.
Chuẩn bị dữ liệu
Trước hết chúng ta cần phải có dữ liệu ảnh và nhãn (images & labels). Dữ liệu đối với mô hình cũng giống những viên gạch cho việc xây nhà, không có dữ liệu thì không xây dựng được mô hình nào cả.
Tập hợp ảnh
Có vài cách để thu thập ảnh cho việc huấn luyện mô hình:
- Tìm trên Open Images Dataset, đây là tập hợp hơn 9 triệu ảnh với 6000 nhóm khác nhau.
- Tìm với công cụ tìm kiếm (Google, Bing, …) với lưu ý cần kiểm tra kỹ về bản quyền sử dụng ảnh.
- Trích xuất các khung hình từ Videos
- Tự chụp ảnh
Trong bài hôm nay, mình dùng thư viện fiftyone để tải ảnh từ Open Images Dataset.
1
2
3
4
5
6
7
dataset = fiftyone.zoo.load_zoo_dataset(
"open-images-v6",
split="train",
label_types=["detections"],
classes=["Panda"],
max_samples=250,
)
Dữ liệu tải về sẽ có 3 thư mục, mình chỉ lấy ảnh thư mục ảnh data để thực hiện việc gán nhãn ở bước tiếp theo.
.
├── data
│ ├── 02a4749df3d7a0c9.jpg
│ ├── 0b5547d4aa16e365.jpg
│ ...
├── labels
│ └── detections.csv
└── metadata
├── classes.csv
├── hierarchy.json
└── image_ids.csv
Gán nhãn
Mình dùng thư viện labelImg cho việc gán nhãn và mất khoảng hơn 1h để gán nhãn cho khoảng 130 ảnh. (Bạn nào biết công cụ nào tiện hơn thì chia sẻ cho mình và mọi người biết nhé).
Bước gán nhãn này thường tốn nhiều thời gian và không thú vị lắm, nhưng tự nhủ không có gạch thì không xây được nhà nên đành cố gắng!

Các bạn lưu ý chọn định dạng YOLO khi xuất các files để đảm bảo định dạng đúng cho việc huấn luyện mô hình sau này.

Mỗi ảnh sẽ có một nhãn (file txt) tương ứng để chứa thông tin về đường bao của đối tượng:
- Mỗi dòng chứa thông tin của một đối tượng
- Mỗi dòng có 5 giá trị chứa thông tin về đối tượng và toạ độ đường bao: đối tượng, toạ độ trung tâm x, toạ độ trung tâm y, chiều rộng, chiều dài.
- Lưu ý là toạ độ đường bao đã được chuẩn hoá về khoảng
(0, 1)(đây là yêu cầu của mô hình YOLO)
Dưới đây là ví dụ về nhãn và file chứa thông tin về đối tượng:

Sắp xếp thư mục ảnh và nhãn
Sau khi đã có ảnh và nhãn, chúng ta có thể sắp xếp thư mục như sau:
custom_dataset
├── custom_dataset.yaml
├── custom_model.yaml
└── images_and_labels
- File cấu hình của tập dữ liệu
custom_dataset.yamlchứa đường dẫn đến thư mục ảnh và thông tin đối tượng.# relative paths from folder yolov5 # . # ├── custom_dataset # └── yolov5 train: ../custom_dataset/images_and_labels/images/train/ val: ../custom_dataset/images_and_labels/images/valid/ # number of classes nc: 1 # class names names: ['panda'] - File cấu hình của mô hình
custom_model.yamlchứa thông tin cấu trúc mạng, ở đây chúng ta dùng cấu trúc mô hình YOLOv5s (cỡ nhỏ) với mục tiêu rút ngắn thời gian huấn luyện và kích thước mô hình. Lưu ý là chúng ta hoàn toàn có thể dùng cấu trúc khác, ví dụ như YOLOv5m, YOLOv5l, YOLOv5x từ YOLOv5 hoặc một cấu trúc mới do chúng ta tự thiết kế.# custom config based on yolov5s, just change number of class nc: 1 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple ... - Thư mục
image_and_labelschứa ảnh và nhãn dùng cho việc huấn luyện mô hình.images_and_labels ├── images │ ├── train │ │ ├── train_001.jpg │ │ ├── train_002.jpg │ │ └── ... │ ├── valid │ │ ├── valid_001.jpg │ │ ├── valid_002.jpg │ │ └── ... │ └── test │ ├── test_001.jpg │ ├── test_002.jpg │ └── ... └── labels ├── train │ ├── train_001.txt │ ├── train_002.txt │ └── ... └── valid ├── valid_001.txt ├── valid_002.txt └── ...- Thư mục
imagesvàlabelschứa ảnh và nhãn tương ứng. - Ảnh và nhãn được chia sẵn thành 2 thư mực
trainvàvalidation(dùng để huấn luyện và kiểm định mô hình). - Thư mục
imagescòn có 1 thư mục contestchứa ảnh dùng để kiểm nghiệm chất lượng mô hình.
- Thư mục
Huấn luyện mô hình
Cài đặt thư viện liên quan
Tải YOLOv5 từ GitHub và các cài đặt các thư viện liên quan.
git clone https://github.com/ultralytics/yolov5 # clone repo
cd yolov5
pip install -r requirements.txt
Lưu ý là chúng ta cần YOLOv5 ở cùng thư mục với custom_dataset ở trên.
.
├── custom_dataset
└── yolov5
Huấn luyện
Các bước chuẩn bị đã xong, giờ việc huấn luyện trở nên rất đơn giản
python train.py --img 416 --batch 16 --epochs 1000 \
--data ../custom_dataset/custom_dataset.yaml \
--cfg ../custom_dataset/custom_model.yaml \
--weights '' --name custom_model --cache
img: kích thước ảnh (độ phân giải)batch: số ảnh dùng để huấn luyện trong mỗi lượtepochs: số lượt huấn luyện cho tất cả các ảnh trong tập dữ liệutraindata: đường dẫn đến file cấu hình của tập dữ liệucfg: đường dẫn đến file cấu hình của mô hìnhweights: đường dẫn đến fileweightchứa độ liên kết giữa các neuron (để''là để huấn luyện từ đầu)name: tên thư mục để lưu mô hìnhcache: dùng bộ nhớ đệm để huấn luyện nhanh hơn
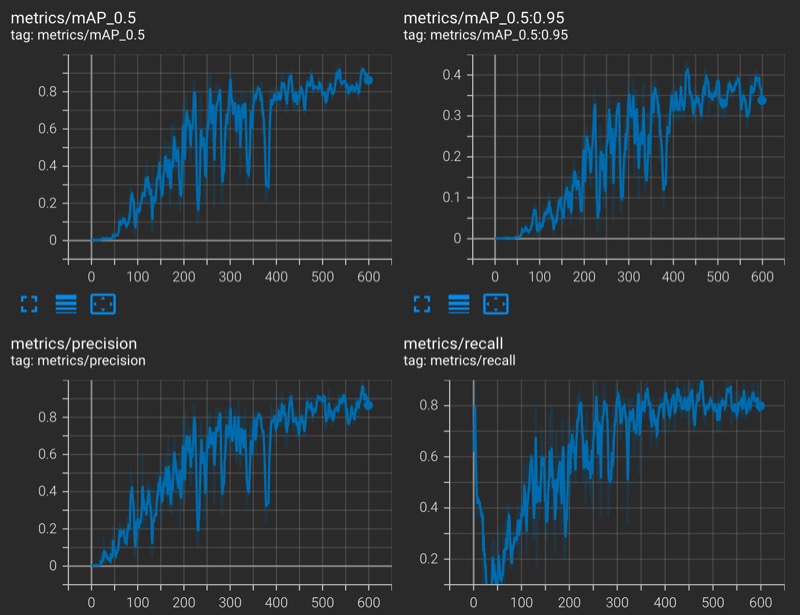
Kết quả
Dùng tensorboard để kiểm tra kết quả của việc huấn luyện (các chỉ số thay đổi như thế nào sau mỗi epoch)
tensorboard --logdir=runs
ls runs/train/custom_model/weights # 'custom_model' was set during training (--name)
# best.pt last.pt
Khi việc huấn luyện kết thúc, có 2 file weights mô hình được lưu lại
- Mô hình tốt nhất:
best.pt(tốt nhất dựa trên chỉ số Average Precision trên tập kiểm định) - Mô hình cuối cùng:
last.pt
Dự đoán với mô hình được huấn luyện
python detect.py --weights runs/train/custom_model/weights/best.pt \
--img 416 --conf 0.4 \
--source ../custom_dataset/images_and_labels/images/test
weights: file weight dùng để dự đoánimg: kích thước ảnh (độ phân giải)conf: độ tin cậysource: đường dẫn đến thư mục ảnh
Kết quả dự đoán được lưu tại thư mục /yolov5/runs/detect/exp1/ (hoặc exp2, 3, … tuỳ vào số lần chúng ta chạy dự đoán với detect.py).

Google Colab và dữ liệu
Mình đã chuẩn bị một Google Colab Notebook để tiện cho việc tham khảo. Các bạn hoàn toàn có thể dùng dữ liệu của mình để dùng với notebook này (chỉ cần chuẩn bị đúng các file cấu hình là ổn).
Bên cạnh đó, mình lưu tập dữ liệu gấu trúc với nhãn ở Panda ML Blog Github để các bạn có thể thực hành làm quen với các bước xây dựng mô hình khi chưa có dữ liệu trong tay.
Tạm kết
Bài hôm nay đã giới thiệu đến các bạn các bước để huấn luyện một mô hình Object Detection dựa trên YOLOv5. Có lẽ bước tốn thời gian nhất là bước tìm ảnh phù hợp và gắn nhãn cho ảnh. Còn các bước huấn luyện và dự đoán thì khá dễ dàng. Trong thực tế cũng vậy, bước chuẩn bị dữ liệu (data preparation) thường cũng là bước tốn thời gian nhất.
Với tập dữ liệu hơn 100 ảnh, mình khá hài lòng với mô hình được huấn luyện khi mô hình này cho kết quả tương đốt ổn. Hy vọng là với bài hướng dẫn này, các bạn cũng sẽ huấn luyện được những mô hình thú vị cho riêng mình.

Leave a comment