
Một bước không thể thiếu trong bất kỳ dự án học máy nào là tìm hiểu và làm quen với dữ liệu. Chúng ta sẽ sử dụng thư viện Pandas trong Python cho việc này. Đây là một trong những thư viện phổ biến nhất được dùng cho việc tìm hiểu và xử lý dữ liệu. Chúng ta thực hiện điều này với lệnh:
import pandas as pd
Thành phần quan trọng nhất trong thư viện Pandas là bảng dữ liệu DataFrame, đây là nơi lưu trữ tất cả thông tin về dữ liệu (giống như bảng tính Excel hoặc một bảng trong cơ sở dữ liệu SQL).
Với thư viện Pandas, chúng ta có thể thực hiện hầu hết các tác vụ với một bảng dữ liệu như trích xuất, lọc bớt, chuyển đổi dữ liệu… Hãy cùng thử một bài thực hành nhỏ với dữ liệu về giá nhà tại Melbourne, Úc dưới đây.
Đọc dữ liệu
# lưu đường dẫn vào biến để dễ dàng sử dụng
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# đọc và lưu dữ liệu vào bảng dữ liệu DataFrame với tên biến melbourne_data
melbourne_data = pd.read_csv(melbourne_file_path)
Mô tả dữ liệu
# in thông tin tóm tắt của dữ liệu
melbourne_data.describe()
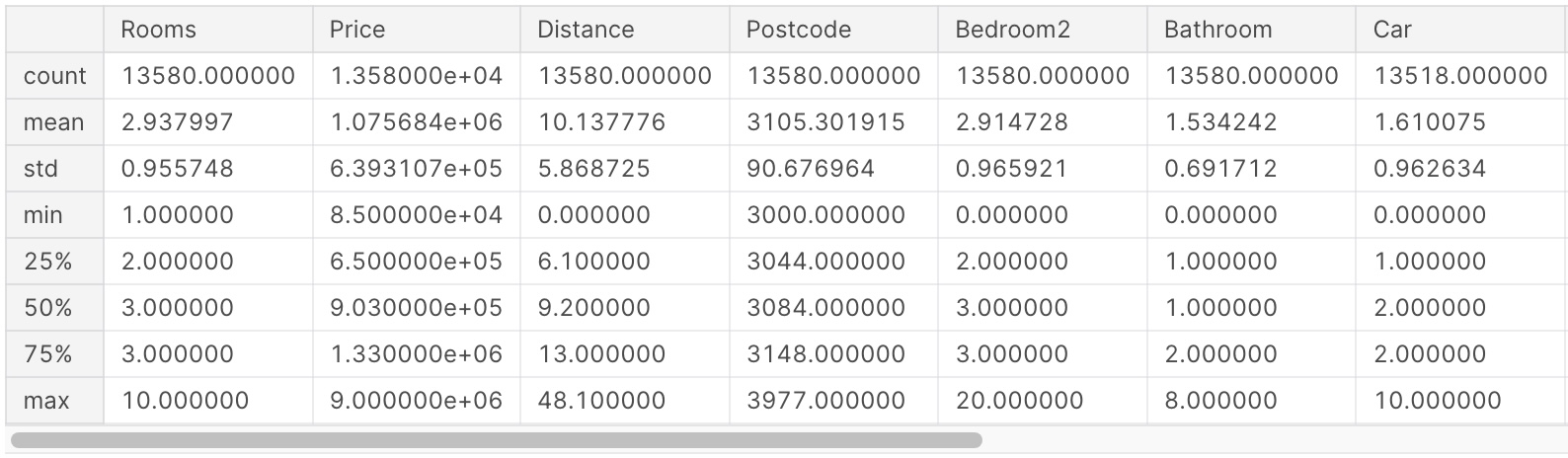
Dòng melbourne_data.describe() cho kết quả là một bảng tổng hợp các thông tin cơ bản của các cột trong dữ liệu melbourne_data. Bảng này bao gồm 8 chỉ số cho mỗi cột trong tập dữ liệu gốc của bạn. Con số đầu tiên count là số lượng, cho biết có bao nhiêu hàng có giá trị không bị thiếu.
Có nhiều nguyên nhân dẫn đến việc dữ liệu bị thiếu (missing data). Ví dụ, một căn nhà với 1 phòng ngủ sẽ không thể có thông tin về kích thước của phòng ngủ thứ 2. Hoặc đôi khi, người thu thập dữ liệu ghi thông tin bị sai (human error). Đây là một chủ đề tương đối thú vị, chúng ta sẽ quay lại chủ đề này sau.
Giá trị thứ hai mean là giá trị trung bình, tiếp đó std là là độ lệch chuẩn (standard deviation), đo lường mức độ phân tán số học của các giá trị.
Các giá trị còn lại là min, 25%, 50%, 75% và max. Hãy tưởng tượng sắp xếp các giá trị trong một cột dữ liệu từ giá trị thấp nhất đến giá trị cao nhất. Giá trị đầu tiên (nhỏ nhất) là min. Nếu bạn đi một phần tư thông qua danh sách, bạn sẽ tìm thấy một số lớn hơn 25% giá trị và nhỏ hơn 75% giá trị. Đó là giá trị 25% (hay được gọi là “percentile thứ 25”). Percentile thứ 50 và thứ 75 được định nghĩa tương tự, và max là số lớn nhất.
Tạm kết
Quá trình tìm hiểu dữ liệu trong thực tế sẽ phức tạp hơn tuỳ thuộc vào bài toán mà chúng ta cần giải quyết và tuỳ thuộc vào kiểu dữ liệu chúng ta có. Trên đây chỉ là một ví dụ đơn giản mà thôi, nhưng quan trọng là chúng ta nhớ rằng đây là một bước quan trọng, tạo tiền đề cho quá trình xây dựng mô hình sau này.

Leave a comment