
Sau khi đã làm quen với dữ liệu, chúng ta có thể bắt đầu xây dựng một mô hình đơn giản để xem mô hình dự đoán đơn giản. Hãy tiếp tục sử dụng dữ liệu về giá nhà tại Melbourne, Úc cho bài hôm nay.
Lựa chọn dữ liệu cho xây dựng mô hình
Đôi khi dữ liệu có quá nhiều biến (đặc trưng) mà bạn không chắc nên dùng biến nào vào việc xây dựng mô hình. Hãy bắt đầu bằng cách lựa chọn một số biến bằng trực giác và kinh nghiệm của mình. Sau khi đã thực hiện bước tìm hiểu dữ liệu, hãy thử tự đánh giá xem những yếu tố nào có khả năng ảnh hưởng lớn nhất đến giá nhà mà chúng ta muốn dự đoán (như vị trí? diện tích, …).
Để chọn các biến, trước hết hãy liệt kê danh sách tất cả các cột trong tập dữ liệu. Điều này được thực hiện thông qua dòng code dưới đây:
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns
Thuộc tính columns chứa tên tất cả các cột của bảng dữ liệu DataFrame(trong trường hợp này là bảng melbourne_data).
# output
Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
Dữ liệu melbourne_data có vài biến bị thiếu giá trị, chúng ta sẽ tìm hiểu về các kỹ thuật xử lý chúng sau này. Còn bây giờ, hãy dùng phương pháp đơn giản nhất là lược bỏ đi những dòng mà không có đầy đủ các đặc điểm trong tập dữ liệu của chúng ta.
melbourne_data = melbourne_data.dropna(axis=0)
Có nhiều cách để chọn một phần dữ liệu của bạn, trong bài này chúng ta sử dụng 2 cách sau đây:
- Dùng cách gọi thuộc tính bằng dấu chấm (dot notation)
- Dùng cách lọc các cột dữ liệu của DataFrame bằng danh sách các cột
Lựa chọn mục tiêu dự đoán
Bạn có thể trích xuất một biến thông qua dấu chấm. Cột giá trị này sẽ được lưu dưới dạng Series, về cơ bản là một bảng dữ liệu DataFrame chỉ với một cột dữ liệu.
Chúng ta sẽ dùng cách này để lựa chọn mục tiêu mà chúng ta muốn dự đoán. Với bài toán dự đoán giá nhà, cột dữ liệu chúng ta quan tâm sẽ là Price. Thông thường, biến mục tiêu sẽ được đặt tên là y (tìm y khi biết x), nên chúng ta có thể dùng code sau:
y = melbourne_data.Price
Chọn các “đặc trưng”
Các cột dữ liệu được sử dụng trong mô hình của chúng ta (và sau đó được sử dụng để đưa ra dự đoán) được gọi là “đặc trưng.” Trong trường hợp của chúng ta, đó sẽ là các cột được sử dụng để xác định giá nhà. Ngoại trừ biến mục tiêu, chúng ta có thể dùng một phần hoặc tất cả các cột của dữ liệu.
Trong bài này, chúng ta sẽ xây dựng mô hình chỉ với một số đặc trưng mà thôi. Sau này, bạn sẽ thấy cách thử nghiệm và so sánh các mô hình được xây dựng với các đặc trưng khác nhau.
Chúng ta có thể chọn các đặc trưng bằng cách cung cấp một danh sách tên cột trong dấu ngoặc vuông. Dưới đây là một ví dụ:
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
Thông thường, dữ liệu chưa các đặc trưng được gọi là X (bài toàn cho biết giá trị X, tìm biến mục tiêu y).
X = melbourne_data[melbourne_features]
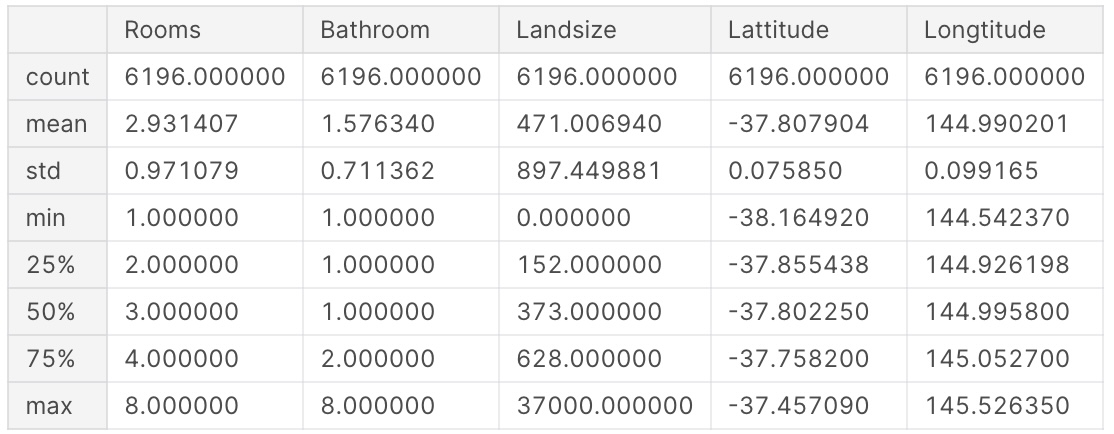
Hãy kiểm tra thử giá trị của những đặc trưng này bằng cách sử dụng phương thức describe (tổng hợp thông tin cơ bản) và head (hiện thị những dòng đầu tiên của dữ liệu).
X.describe()
X.head()
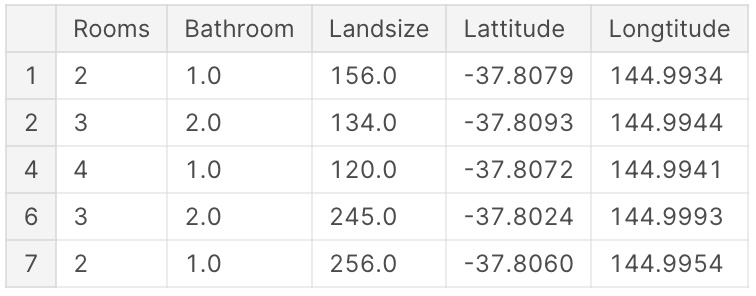
Những bước kiểm tra dữ liệu trực quan như trên có vai trò khá quan trọng. Đôi khi, bạn sẽ gặp phải những điểm bất thường trong dữ liệu mà cần kiểm tra sâu hơn.
Xây dựng mô hình
Để phát triển mô hình, chúng ta sẽ sử dụng thư viện scikit-learn. Đây là thư viện phổ biến nhất cho việc phát triển các mô hình với dữ liệu dạng bảng.
Các bước để xây dựng và sử dụng mô hình như sau: (1) Xác định (define): dùng mô hình nào với các tham số là gì? (2) Huấn luyện (fit): học các tín hiệu và quy luật của dữ liệu, đây là phần cốt lõi của việc xây dựng mô hình. (3) Dự đoán (predict): đúng như tên gọi, đây là bước thực hiện việc dự đoán với mô hình có được ở bước (2) (4) Đánh giá (evaluate): xác định độ chính xác của mô hình.
Dưới đây là một ví dụ về việc khởi tạo một mô hình cây quyết định bằng scikit-learn và thực hiện việc huấn luyện mô hình với các đặc trưng và biến mục tiêu.
from sklearn.tree import DecisionTreeRegressor
# Khởi tạo mô hình, gán giá trị cho biến random_state để đảm bảo kết quả giống nhau trong nhiều lần chạy
melbourne_model = DecisionTreeRegressor(random_state=1)
# Huấn luyện mô hình
melbourne_model.fit(X, y)
Nhiều mô hình học máy sử dụng việc lựa chọn ngẫu nhiên trong quá trình huấn luyện. Do đó, gán giá trị cho biến random_state đảm bảo rằng bạn sẽ có kết quả giống nhau trong mỗi lần chạy. Ví dụ trên dùng giá trị 1 nhưng chúng ta có thể sử dụng bất cứ số nào, chất lượng của mô hình không phụ thuộc quá nhiều vào giá trị này.
Sau khi mô hình được huấn luyện, chúng ta có thể sử dụng để đưa ra dự đoán giá cho một căn nhà bất kì.
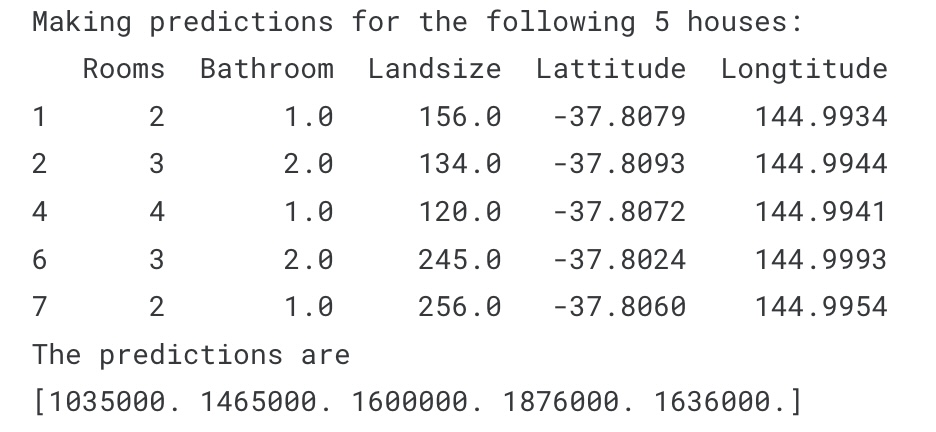
Trong thực tế, chúng ta cần đưa ra dự đoán cho những ngôi nhà mới xuất hiện trên thị trường thay vì các ngôi nhà mà chúng ta đã biết. Nhưng ở đây, chúng ta sẽ đưa ra dự đoán cho một số dòng đầu tiên của tập dữ liệu huấn luyện:
print("Thực hiện dự đoán cho 5 căn nhà sau:")
print(X.head())
print("Giá dự đoán")
print(melbourne_model.predict(X.head()))
python code
X = data[features]
y = data[target]
model = DecisionTreeRegressor(random_state=1)
model.fit(X, y)
model.predict(X.head())
Tạm kết
Đến đây, chúng ta đã làm quen với 3 bước đầu của quá trình xây dựng mô hình. Liệu mô hình này đã đủ tốt hay chưa? Bạn hãy đón đọc bài tiếp theo để tìm ra câu trả lời nhé.

Leave a comment