
Bài hôm nay chúng ta sẽ tìm hiểu các mô hình học máy hoạt động như thế nào và được sử dụng ra sao. Các bạn có thể sẽ thấy nội dung quá cơ bản nếu đã từng xây dựng mô hình thông kê hoặc học máy trước đó. Nếu thế thì chắc các bạn vào nhầm link rồi, bài viết này nằm trong series dành cho các bạn mới làm quen với học máy thôi.
Mô hình học máy
Trước hết hãy thử tưởng tượng tình huống sau đây: Một người họ hàng của bạn kiếm được khá nhiều tiền thông qua việc mua bán bất động sản. Anh ấy đã đề nghị trở thành đối tác kinh doanh với bạn vì biết bạn có sở thích lĩnh vực khoa học dữ liệu. Anh ấy sẽ phụ trách vấn đề về tài chính, còn bạn sẽ cung cấp các mô hình dự đoán giá trị của các căn nhà khác nhau.
Bạn hỏi anh họ cách anh ấy đã dự đoán giá trị bất động sản trước đây, và anh ấy nói rằng đó chỉ là trực giác và kinh nghiệm. Nhưng sau khi trao đổi thêm, bạn mới phát hiện ra rằng anh ấy đã dựa vào đặc điểm của những căn nhà đã được rao bán, và đưa ra dự đoán cho các căn nhà mới mà anh ấy đang xem xét.
Mô hình học máy hoạt động theo cách tương tự, dựa vào các đặc điểm có sẵn trong dữ liệu để đưa ra dự đoán trên các dữ liệu mới. Chúng ta sẽ bắt đầu tìm hiểu mô hình được gọi là Cây Quyết Định (Decision Tree). Đây không phải là mô hình có độ chính xác tối ưu nhất nhưng tương đối dễ hiểu và là một phần cơ bản của một số mô hình tốt nhất trong lĩnh vực khoá học dữ liệu hiện nay.
Mô hình Cây Quyết Định
Trước hết, chúng ta hãy bắt đầu với một mô hình cây quyết định đơn giản như sau: căn nhà nào có hơn 2 phòng ngủ sẽ có giá là 188,000 đô, còn những căn từ 2 phòng ngủ trở xuống thì sẽ có giá 178,000 đô mà thôi.
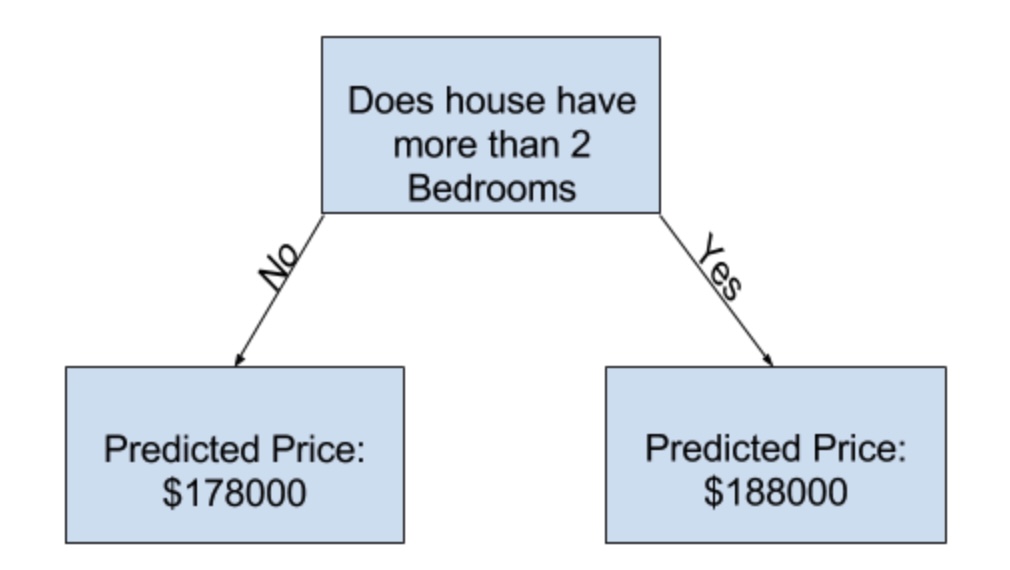
Dựa trên dữ liệu sẵn có, mô hình chia các căn nhà làm 2 nhóm dựa trên số phòng ngủ, và dự đoán giá nhà cho từng nhóm. Quá trình tìm ra quy luật này được gọi là huấn luyện mô hình (fitting / training) và dữ liệu sử dụng được gọi là tập huấn luyện (training data). Sau khi mô hình được huấn luyện, chúng ta có thể sử dụng nó để dự đoán giá của những căn nhà không nằm trong tập dữ liệu của chúng ta.
Cải tiến mô hình Cây Quyết Định
Dưới đây là 2 mô hình cây quyết định khác nhau, bạn nghĩ mô hình nào chính xác hơn?
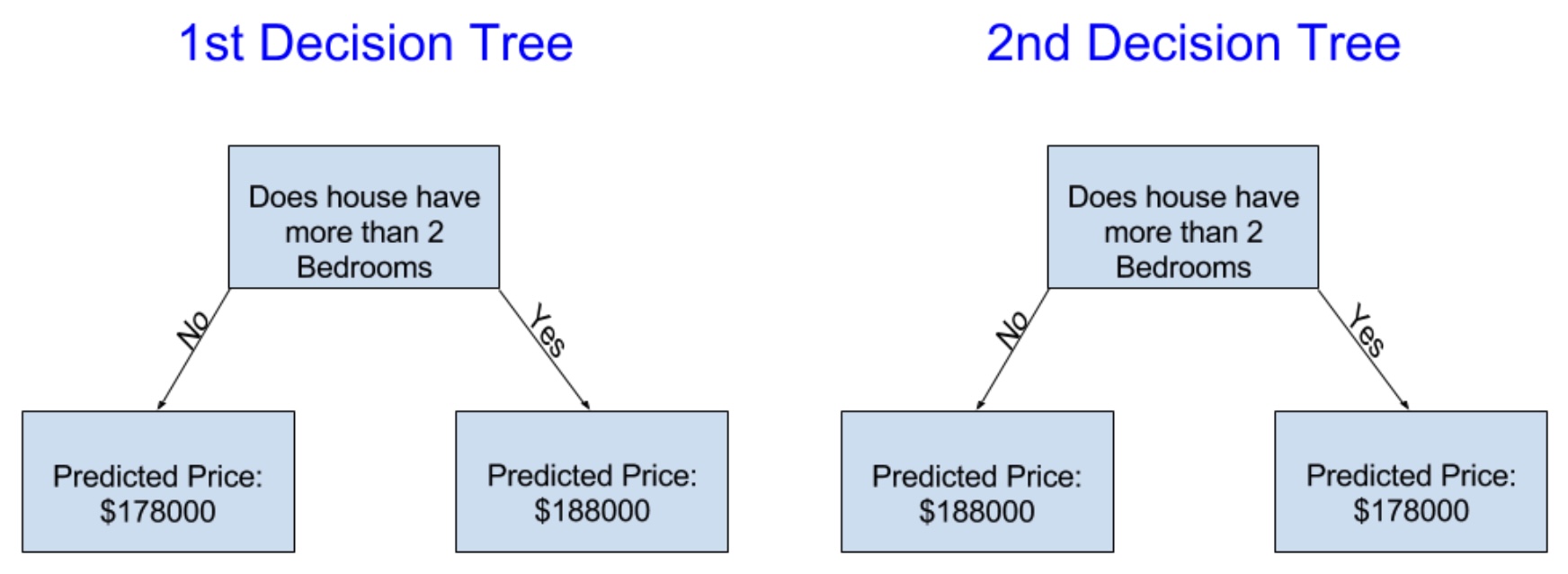
Mô hình bên trái có vẻ sẽ hợp lý hơn vì mô hình này cho thấy căn nhà với nhiều phòng ngủ thường sẽ có giá cao hơn. Tuy nhiên, chắc chắn mô hình này cũng không quá chính xác vì no chỉ dựa trên số phòng ngủ mà chưa xem xét đến những đặc điểm khác như tổng diện tích, vị trí, số phòng tắm … (rõ ràng nhà ở trung tâm sẽ đắt hơn nhiều so với nhà ở ngoại ô).
Chúng ta hoàn toàn có thể xây dựng mô hình bao gồm những đặc điểm nói trên bằng cách dùng Cây Quyết Định với nhiều phân nhánh (splits) hơn. Mô hình như vậy được coi là có độ phức tạp cao hơn với nhiều quy luật nhỏ hơn. Dưới đây là ví dụ của một mô hình dựa trên 2 yếu tố là số phòng ngủ và diện tích căn nhà.
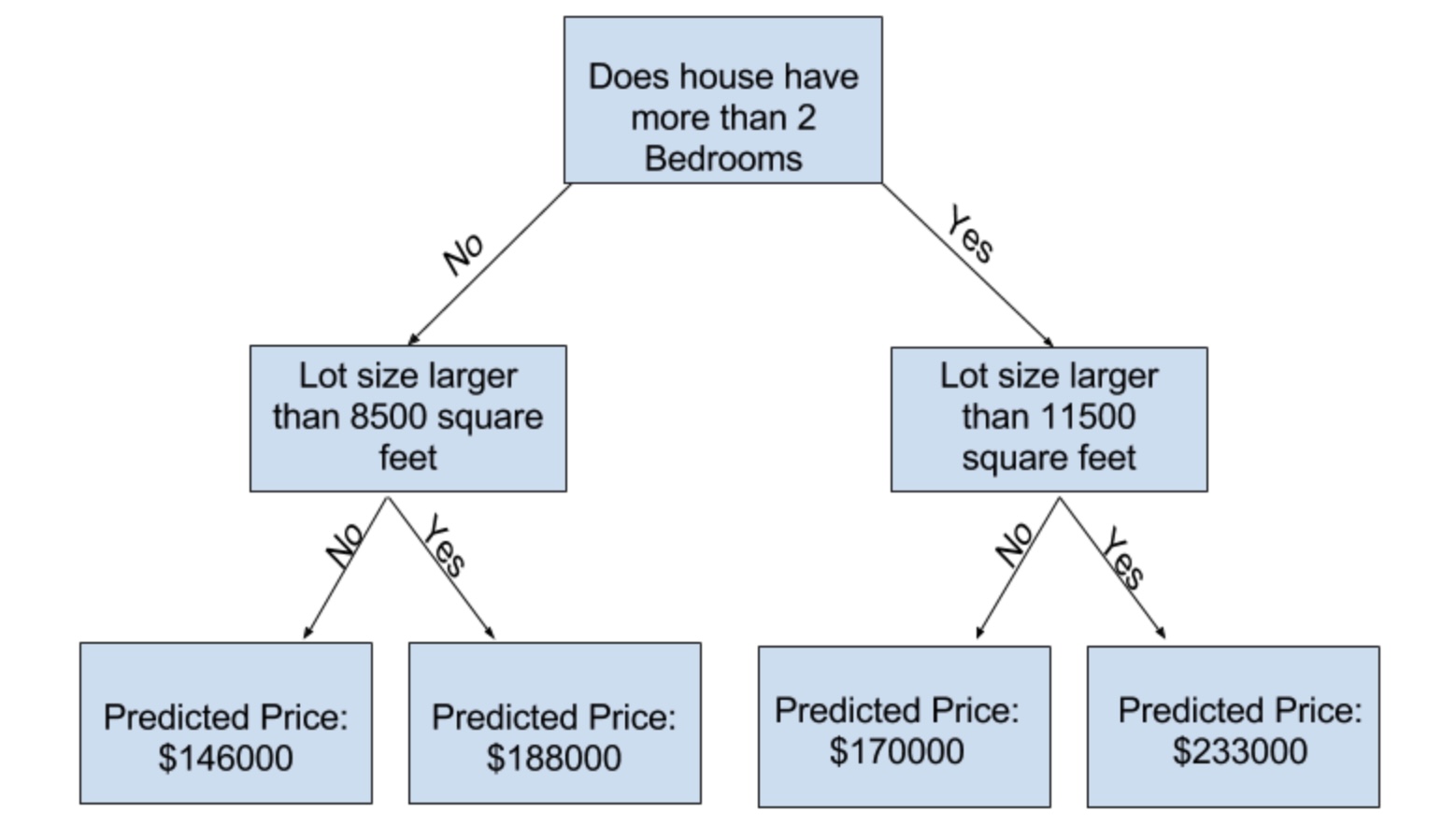
Chúng ta có thể dự đoán một căn nhà bất kì bằng cách đi theo các nhánh của Cây Quyết Định dựa trên các đặc điểm của căn nhà đó. Điểm cuối của mỗi nhánh được gọi là lá (leaf), mỗi lá tương ứng với 1 nhóm và sẽ chúng ta sẽ có giá dự đoán các ngôi nhà trong cùng một nhóm với đặc trưng giống nhau. Ví dụ một căn nhà có 2 phòng ngủ và diện tích dưới 8500 square feet (~790 m2) sẽ có giá là 146,000 đô.
Tạm kết
Qua bài hôm nay, chúng ta đã hiểu cách mô hình học máy hoạt động thông qua ví dụ với mô hình Cây Quyết Định. Chúng ta cũng đã làm quen một số khái niệm cơ bản như huấn luyện mô hình, dự đoán, phân nhánh trong cây quyết định…
Các mô hình học máy thì đều tìm các quy luật từ tập dữ liệu cho trước. Vì vậy, hãy thử tìm hiểu về dữ liệu trong bước tiếp theo.

Leave a comment