
Hiện nay, chatbot đã trở thành một công cụ quan trọng cho các doanh nghiệp để cung cấp thông tin và tăng tương tác đối với khách hàng. Trong số các loại chatbot, retrieval-based chatbot là một trong những phương pháp phổ biến nhất được sử dụng để đáp ứng các yêu cầu và câu hỏi của người dùng.
Trong bài hôm nay, chúng ta sẽ tìm hiểu sơ lược về retrieval-based chatbot và các thành phần NLP cấu thành nên loại chatbot này.
Retrieval based Chatbots
Chatbot thuộc dạng retrieval based có thể trả lời những câu hỏi thường gặp của khách hàng, hay thông tin về sản phẩm, giá bán, khuyến mãi, … đây đều là những thông tin dựa trên dữ liệu sẵn có, chatbot sẽ tìm kiếm và trích xuất thông tin phù hợp.
Ưu điểm của loại chatbot này
- Độ chính xác cao: do câu trả lời dựa trên nguồn dữ liệu có sẵn, câu trả lời thường có độ chính xác cao và đáng tin cậy
- Triển khai dễ dàng: các câu hỏi và câu trả lời có thể được mở rộng dễ dàng
Các thành phần NLP trong Retrieval-based Chatbots
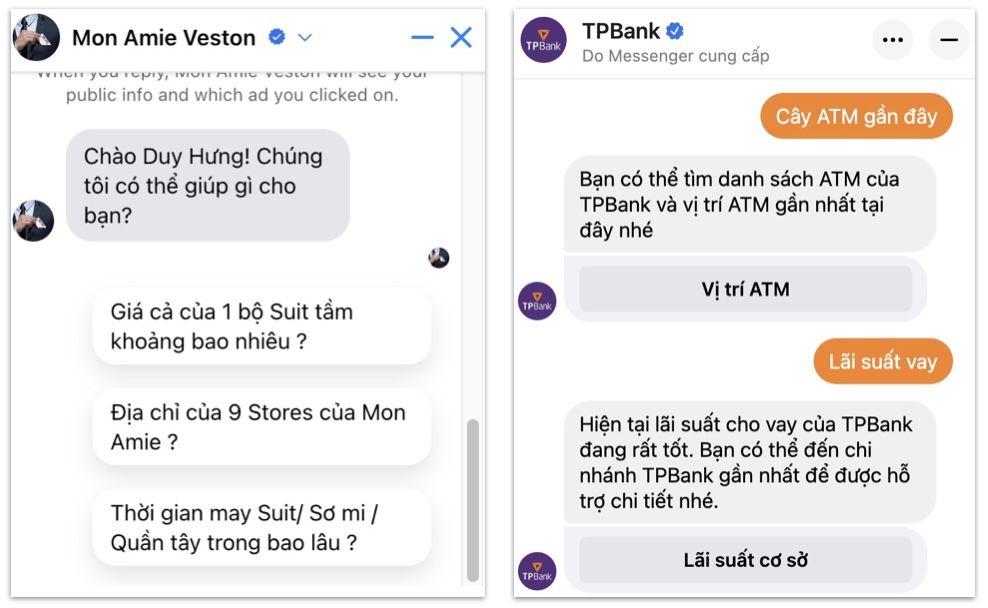
Chúng ta hãy thử tìm hiểu ví dụ về một chatbot của ngân hàng (trợ lý ảo) có khả năng hỗ trợ người dùng với những câu hỏi thường gặp như sau:
- Cây ATM ở đâu?
- Làm thế nào để thay đổi mật khẩu?
- Làm thế nào để đăng kí thẻ tín dụng?
Có nhiều cách để xây dựng một chatbot như trên, nhưng thông thường các bạn sẽ cần làm việc với những bài toán xử lý ngôn ngữ (NLP) nhỏ hơn:
- Xác định mục đích của người dùng (Intent classification)
- Trích xuất thông tin (Information extraction)
- Tìm kiếm thông tin liên quan (Information retrieval)
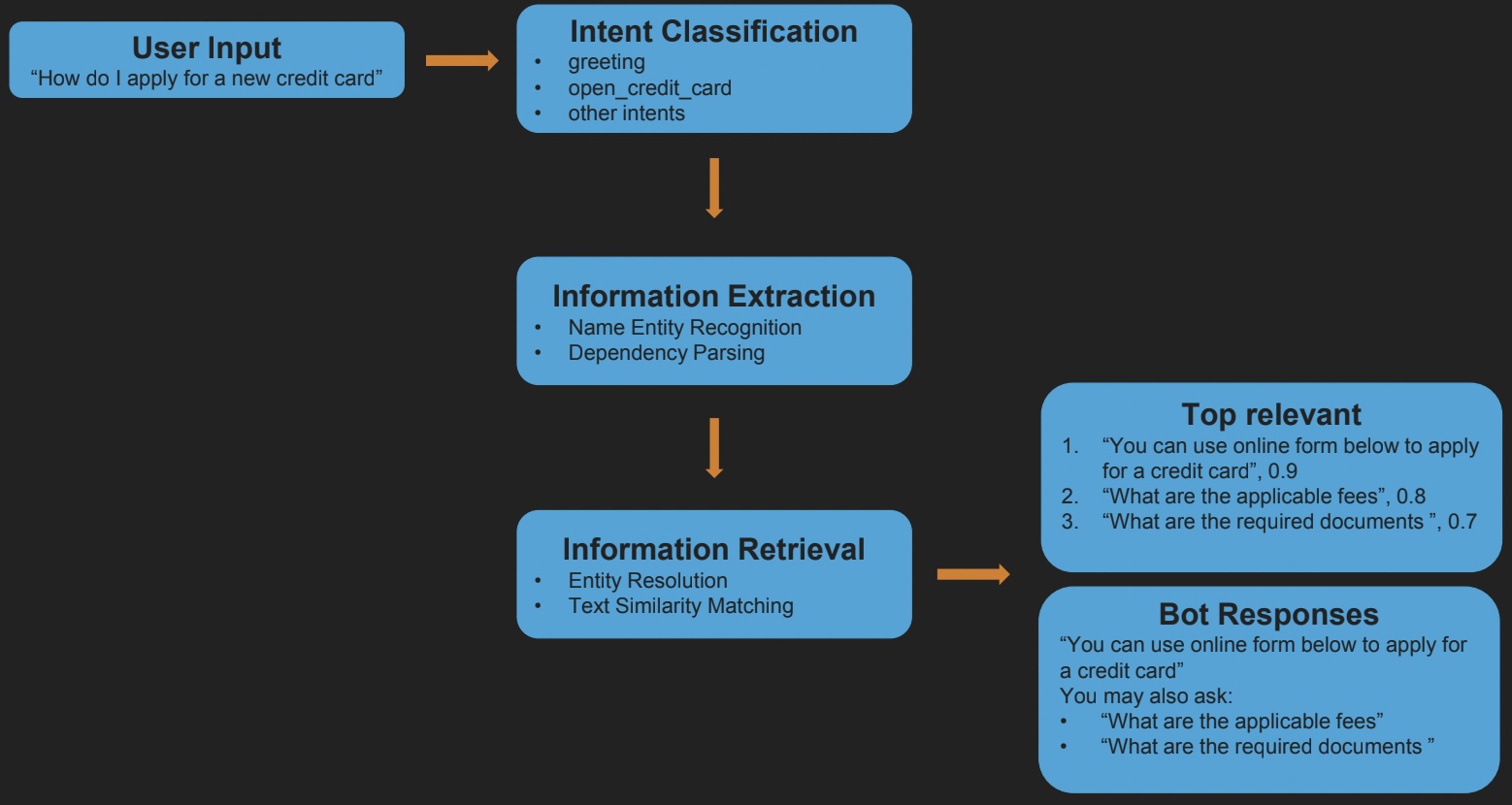
Xác định mục đích (Intent classification)
Đây là quá trình xác định mục đích của người dùng khi nói chuyện với chatbot. Mỗi khi người dùng chat gì đó, chatbot cần phân biệt được người dùng đang chào hỏi xã giao, hay muốn hỏi về một chủ đề cụ thể nào đó. Ví dụ như với câu “chào bạn”, chatbot cần biết đây là câu chào hỏi thông thường. Hoặc với câu “Làm thế nào để đăng ký thẻ tín dụng?”, chatbot cần hiểu người dùng đang muốn mở thẻ tín dụng để tìm câu trả lời cho phù hợp.

Quá trình xây dựng mô hình xác định mục đích người dùng thường yêu cầu huấn luyện trên một tập dữ liệu có nhãn (các câu chat với mục đích tương ứng) và bao gồm các bước sau:
- Làm sạch dữ liệu đầu vào
- Lược bỏ chữ cái thừa
- Chia nhỏ đoạn văn thành các đơn vị từ cơ bản (tokenization)
- Chuẩn hoá dữ liệu đầu vào
- Sửa ngữ pháp
- Biểu diễn dữ liệu từ ngữ / văn bản (text) sang số học (numerical)
- Bag-of-words: biểu diễn văn bản dựa tần số xuất hiện của các từ (câu “cây ATM ở đâu?” có thể biểu diễn bằng
{"cây": 1, "ATM": 1, "ở": 1, "đâu": 1}) - TF-IDF (Term Frequency-Inverse Document Frequency): phương pháp này cũng biểu diễn văn bản dựa trên tần số xuất hiện của các từ, nhưng được điều chỉnh bằng độ phổ biến của từ trong tập dữ liệu (các trợ từ “những, thì, là” có thể xuất hiện nhiều nhưng không mang nhiều ý nghĩa quan trọng)
- Word Embeddings: biểu diễn từ dựa trên không gian vector nhiều chiều, trong đó các từ có ý nghĩa tương tự sẽ ở gần nhau.
- Bag-of-words: biểu diễn văn bản dựa tần số xuất hiện của các từ (câu “cây ATM ở đâu?” có thể biểu diễn bằng
- Mô hình phân loại
- Khớp từ khoá (key word matching)
- Mô hình học máy có giám sát (supervised machine learning)
Trích xuất thông tin (Information Extraction)
Sau khi xác định được mục đích của người dùng, chatbot cần trích xuất những thông tin cần thiết. Ví dụ như với câu “Làm thế nào để đăng ký thẻ tín dụng?”, chủ đề quan trọng ở đây là thẻ tín dụng với mục tiêu đăng ký.
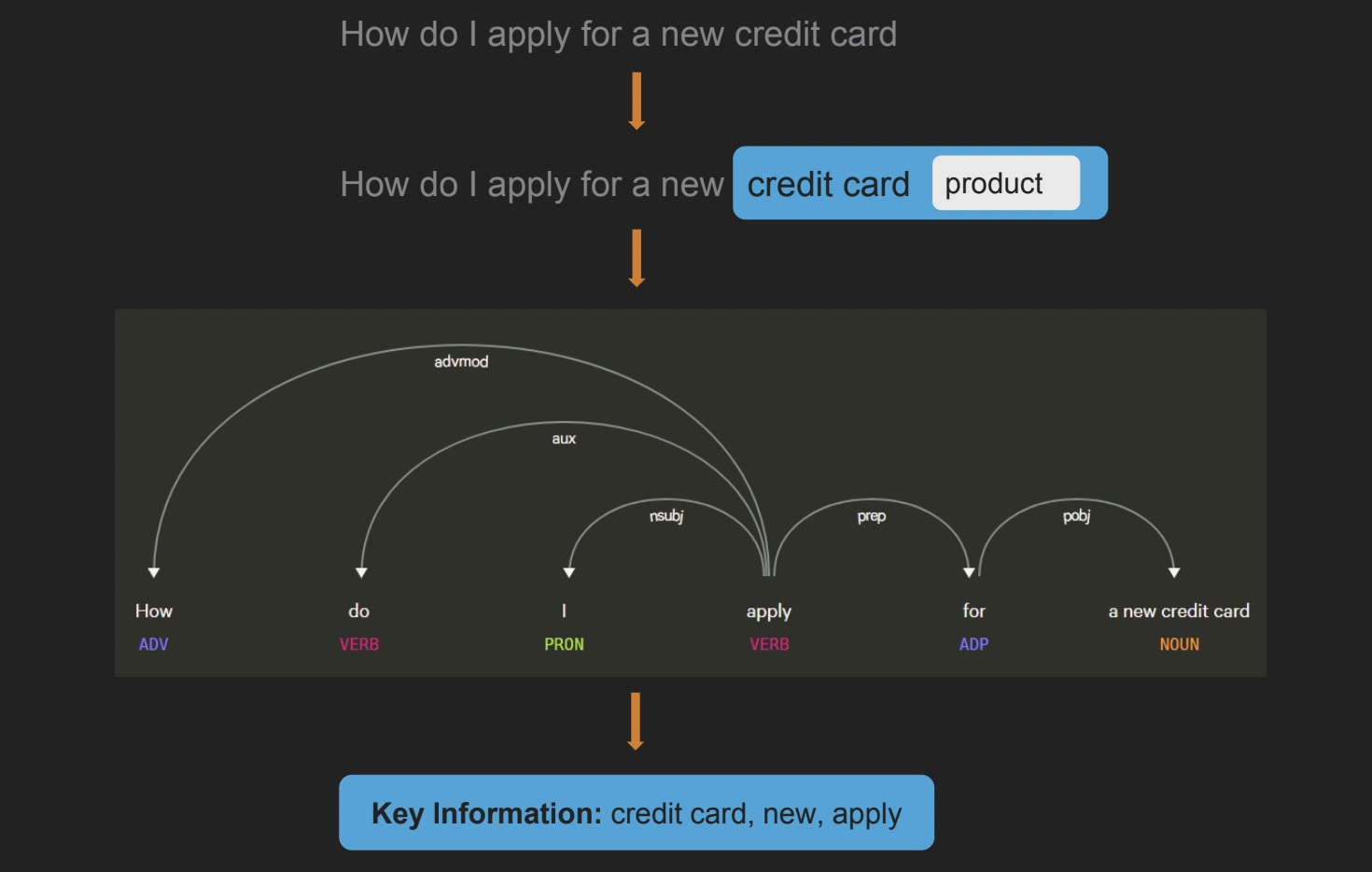
Quá trình trích xuất thông tin thường bao gồm những bước sau:
- Phân loại từ loại (part of speech tagging): phân tích ngữ pháp và xác định từ loại tương ứng (danh từ, động từ, tính từ, …)
- Xác định mối quan hệ phụ thuộc (dependency parsing): phân tích cấu trúc câu và xác định các từ liên quan đến nhau như thế nào
- Phân loại đối tượng (Named entity recognition): xác định các thông tin đặc biệt như địa chỉ, ngày tháng, số điện thoại, …
Thông qua quá trình này, chatbot sẽ trích xuất được thông tin quan trọng đề tìm được câu trả lời thích hợp nhất.
Tìm kiếm thông tin (Information Retrieval)
Khi đã có được những thông tin chính từ câu hỏi của người dùng thì không quá khó để chatbot tìm kiếm trong nguồn dữ liệu có sẵn và trích xuất thông tin liên quan. Nguồn dữ liệu này có thể là một cơ sở dữ liệu những câu hỏi thường gặp, mẫu đăng ký, trang web liên quan, hồ sơ người dùng, …
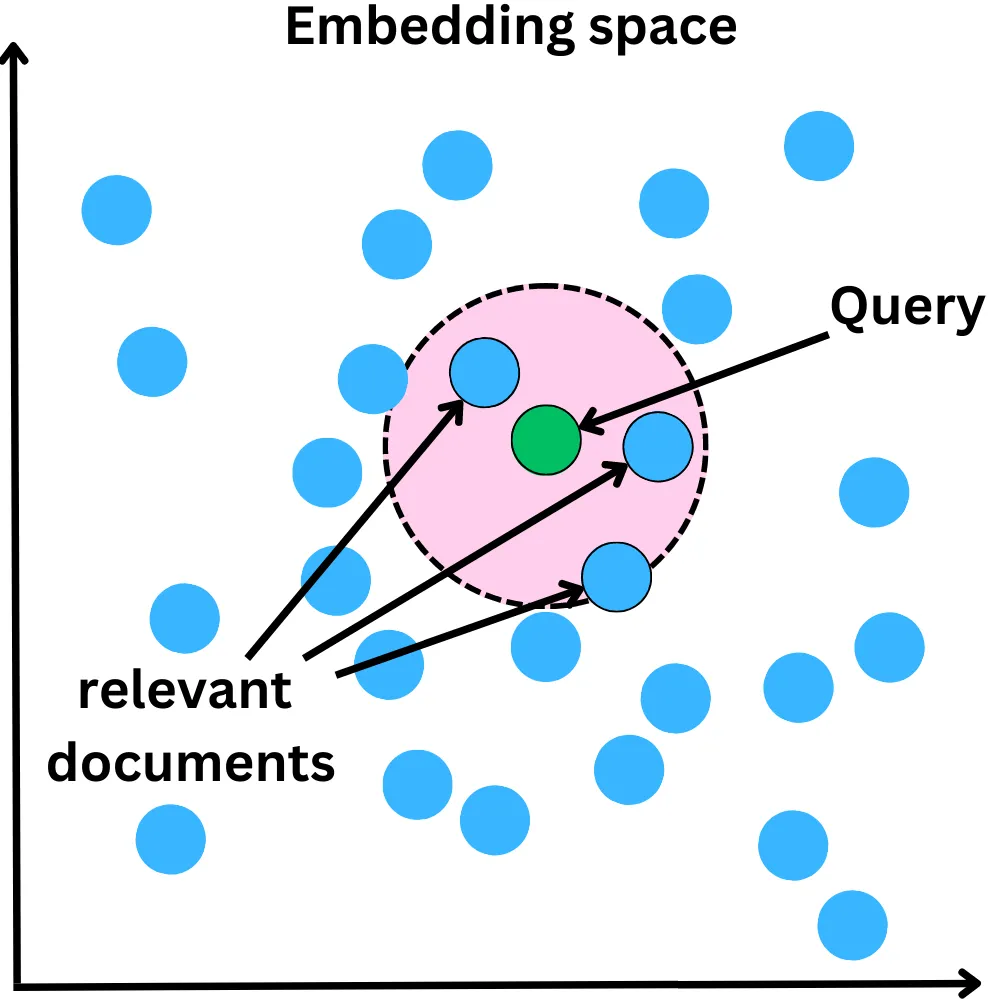
Một phương pháp có độ chính xác cao ở bước này là áp dụng word embeddings cho cả câu hỏi đầu vào và cơ sở dữ liệu sẵn có để tìm được những thông tin liên quan nhất. Hiểu nôm na là các câu hỏi và văn bản có thể được biểu diễn bằng các điểm toạ độ trên trục xy, nếu khoảng cách giữa 2 điểm càng gần nhau, khả năng 2 văn bản chứa các thông tin liên quan là càng cao.
Tạm kết
Trên đây là một số bài toán NLP hay gặp trong retrieval based chatbot. Đây đều là những bài toán cơ bản trong xử lý ngôn ngữ tự nhiên nên nếu các bạn làm về mảng này thì sẽ còn gặp lại dài dài :)
P/S: các bạn đã xây dựng chatbot loại này chưa? Có phương pháp nào hay và chính xác thì cùng chia sẻ nhé.

Leave a comment