
ChatGPT là một trong những mô hình ngôn ngữ có khả năng tạo ra câu trả lời chính xác và mạch lạc trong nhiều lĩnh vực khác nhau. ChatGPT được xây dựng bởi sự kết hợp giữa phương pháp học có giám sát (Supervised Learning) và học tăng cường với phải hồi người dùng (Reinforment Learning with Human Feedback - RLHF). Tuy nhiên, phương pháp học tăng cường RLHF mới thực sự làm nên sự khác biệt của ChatGPT.
Vậy phương pháp RLHF là gì? Hãy cùng tìm hiểu về RLHF trong bài hôm nay.
Giới thiệu về học tăng cường (Reinforcement Learning)
Trước hết, hãy làm quen với một số khái niệm trong học tăng cường (Reinforment Learning - RL). Ý tưởng của RL là một AI sẽ tương tác với môi trường và nhận được phần thưởng tương ứng mới từng quyết định và hành động khác nhau. Thông qua quá trình này, AI sẽ dần trở nên thông minh hơn và biết cách tối ưu hoá phần thưởng của mình.
Hãy tưởng tượng chúng ta đưa cho cậu em trai một trờ chơi điện tử mới.

Cậu ta sẽ tương tác với trò chơi (môi trường) bằng cách bấm nút trên tay cầm. Khi nhận được đồng xu và số điểm tăng lên (phần thưởng), cậu ta sẽ hiểu rằng cần phải lấy các đồng xu trong trò chơi này.
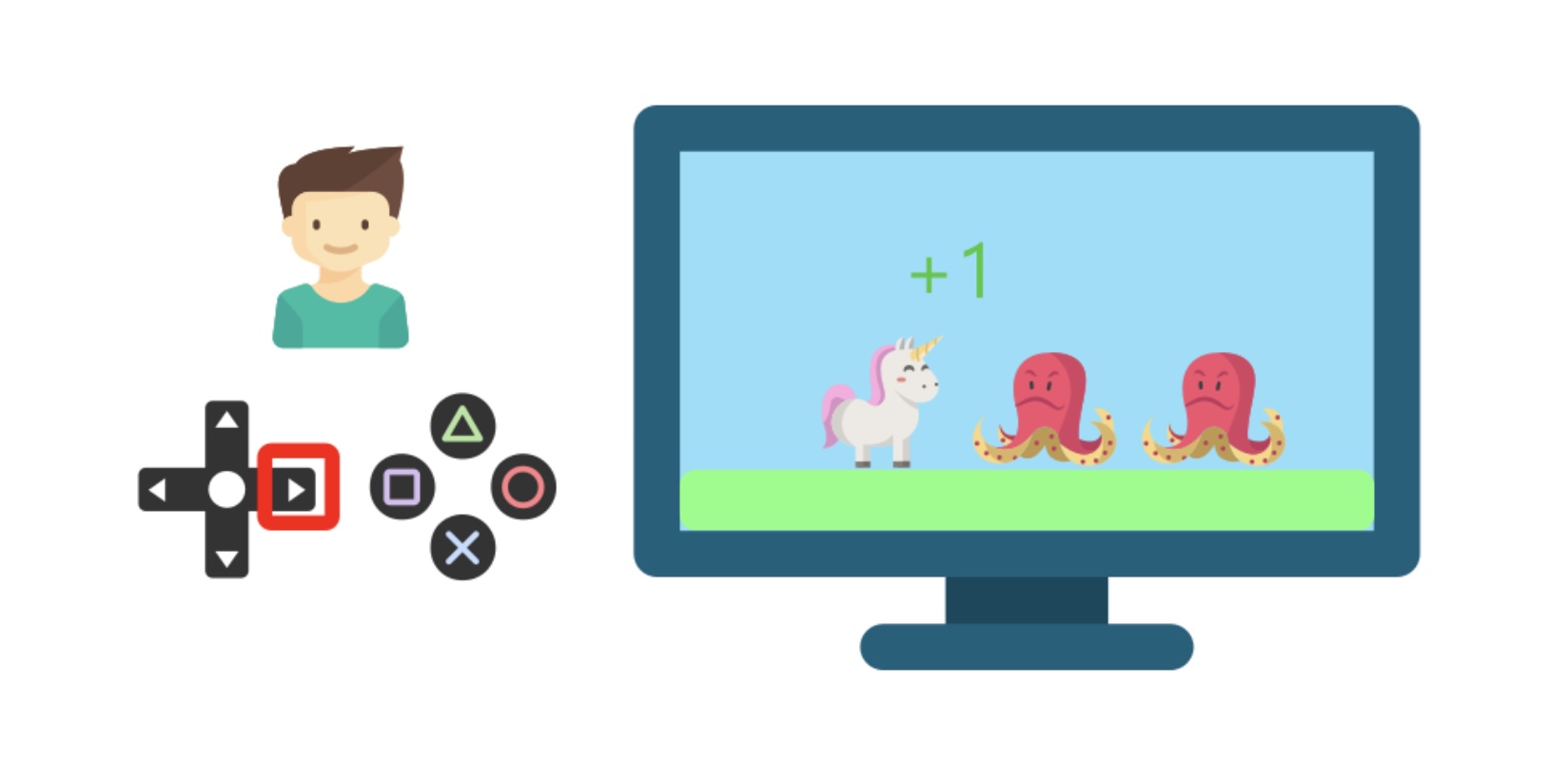
Ngược lại, khi đụng phải các con vật, nhân vật trong trong trò chơi bị chết và số điểm bị giảm xuống, cậu ta sẽ hiểu rằng nên tránh những con vật “nguy hiểm” để tiếp tục trò chơi.
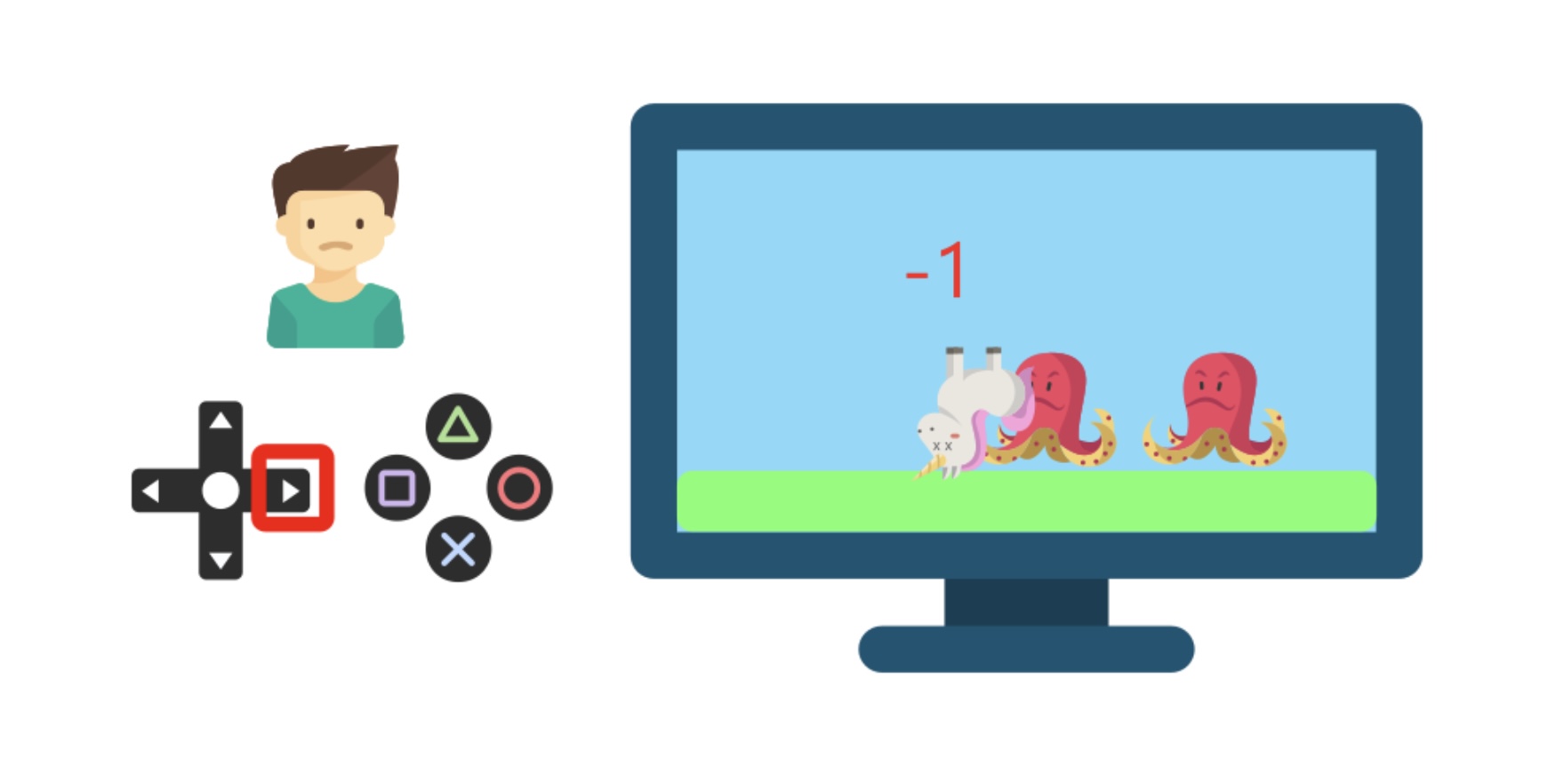
Cứ tiếp tục như vậy, cậu em trai này sẽ có thể tự chơi mà không cần sự hướng dẫn của người khác. Đây chính là một ví dụ thực tế cho việc “học dựa trên tương tác với môi trường”, và RL mô phỏng quá trình này như sau:
Ở từng trạng thái (State), AI (hay Agent) thực hiện các hành động (Action) trong môi trường (Environment) và nhận được phần thưởng (Reward) tương ứng. Agent sẽ học được cách chơi hiệu quả (Policy) để tối ưu phần thưởng nhận được.
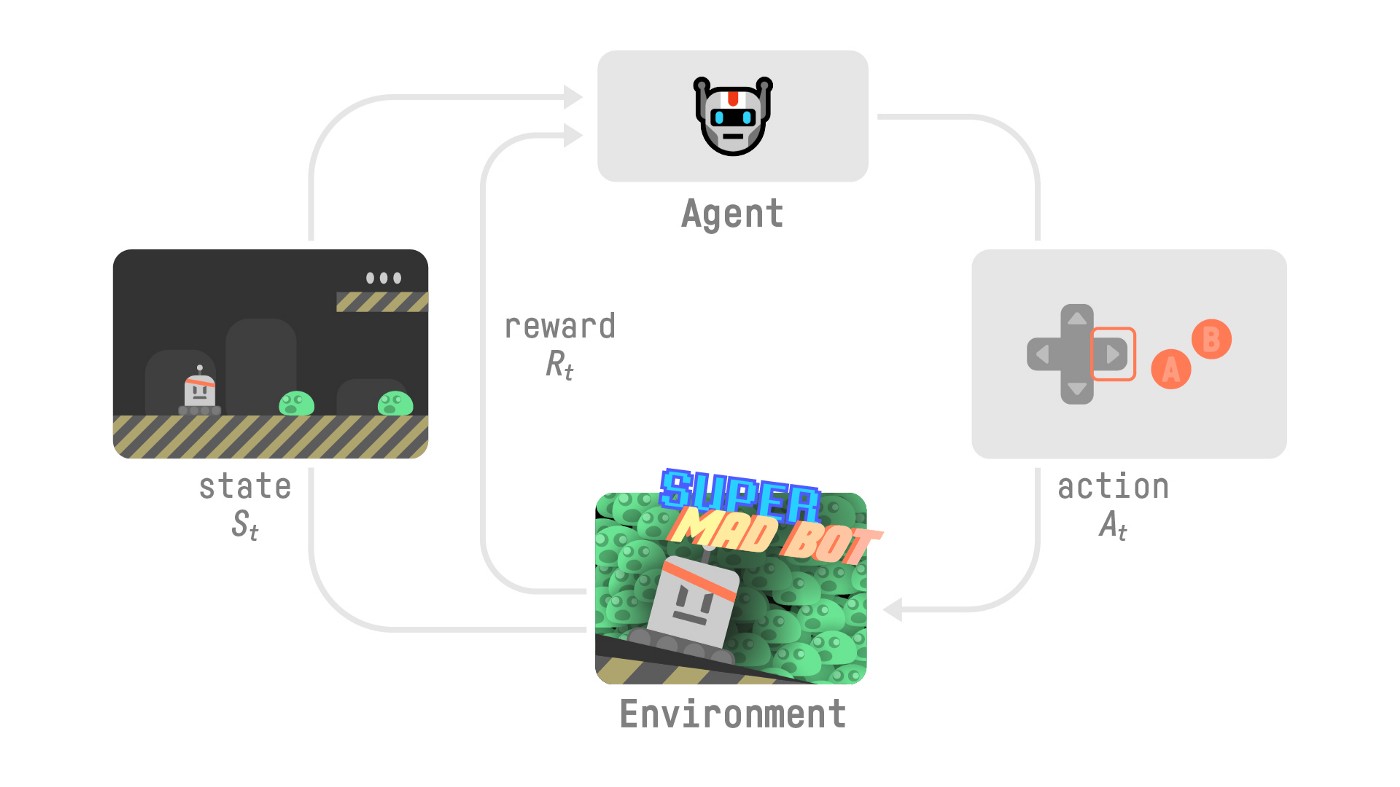
Lấy ví dụ một AI học cách chơi trò chơi điện tử, tại mỗi thời điểm t:
- AI ở trạng thái
Sttrong môi trường - Dựa trên trạng thái này, AI thực hiện hành động
At(ví dụ như di chuyển) - Môi trường chuyển sang trạng thái mới
St+1(khung hình mới) - Phần thưởng cho AI là
Rt(số điểm tăng lên khi ăn xu) - Quá trình tiếp diễn và AI sẽ học được cách chơi (Policy) phù hợp
Giới thiệu về RLHF
RLHF là gì?
Reinforcement Learning from Human Feedback (RLHF) là phương pháp kết hợp Reinforcement Learning với sự hướng dẫn của con người để cải thiện quá trình huấn luyện mô hình. Trong RFHL, AI vừa thực hiện các hành động tương tác với môi trường, vừa nhận phản hồi từ người dùng về chất lượng các hành động đó. Điều này giúp cho quá trình huấn luyện trở nên hiệu quả hơn, đặc biệt trong một môi trường phức tạp và rất khó xác định trước hàm phần thưởng (Reward) trong mô hình RL.
RLHF cho mô hình ngôn ngữ
Một điều thú vị là mô hình ngôn ngữ (Language model) có thể được xem như một bài toán Reinforment Learning. Trong đó, mô hình (Agent) sẽ tương tác với môi trường (nhiệm vụ trả lời tự động) và học cách trả lời (chọn từ ngữ và cách trả lời) để tối ưu phần thưởng (trả lời tự nhiên và chính xác).
Để cải thiện mô hình ngôn ngữ, RLHF sử dụng đánh giá của con người cho những văn bản để huấn luyện mô hình có khả năng tạo ra ngôn ngữ chính xác và phù hợp với ngữ cảnh hơn.
ChatGPT sử dụng RLHF ra sao

RLHF được dùng để xây dựng ChatGPT gồm 3 bước chính:
Bước 1: Tinh chỉnh mô hình ngôn ngữ cho đoạn hội thoại
Với ChatGPT, một danh sách các câu hỏi (prompt) được lựa chọn và các cộng tác viên (Labellers) sẽ viết câu trả lời dự kiến tương ứng. Dữ liệu này được dùng để tinh chỉnh (fine-tunine) mô hình ngôn ngữ sẵn có (như GPT) sao cho phù hợp với ngữ cảnh của một cuộc hội thoại.
Bước 2: Xây dựng hàm phần thưởng mô phỏng lựa chọn của người dùng
Ở bước này, với mỗi câu hỏi, vài câu trả lời được tạo ra từ mô hình, sau đó nhóm cộng tác viên sẽ đánh giá và xếp hạng các câu trả lời này. Thông tin này sẽ được dùng để xây dựng hàm phần thưởng (điểm số cho câu trả lời) trong mô hình học tăng cường.
Bước 3: Tối ưu mô hình ngôn ngữ để có cách trả lời tốt hơn
Ở bước này, mô hình học tăng cường áp dụng hàm phần thưởng có được ở bước (2) (Reward model) để tối ưu cách tạo ra câu trả lời (Policy) với mục đích đạt được phản hồi tích cực nhất từ người dùng.
Trong 3 bước kể trên, bước 2 và bước 3 sẽ được lặp lại nhiều lần để liên tục nâng cao khả năng trả lời chính xác, mạch lạc và phù hợp với ngữ cảnh của mô hình.
Ưu điểm nhược điểm của RLHF
Với cách tiếp cận độc đáo, RLHF có những ưu điểm tiêu biểu như sau:
- Độ phù hợp: mô hình sẽ có đồ phù hợp với mục đích của con người hơn mô hình RL truyền thống.
- Độ thích ứng: cho phép huấn luyện mô hình để phù hợp với mục đích khác một cách dễ dàng.
- Khả năng cập nhật liên tục: RLHF có thể được áp dụng với phản hồi mới để nâng cao chất lượng mô hình.
Ngược lại RLHF cũng nhược điểm cần lưu ý là phụ thuộc rất lớn vào chất lượng phản hồi của người dùng. Bên cạnh việc đòi hỏi một lượng phản hồi đủ lớn và đa dạng, chất lượng của mô hình sẽ có thể bị ảnh hưởng bởi những yếu tố chủ quan:
- Thiết kế của nhóm nghiên cứu về cách thu thập dữ liệu
- Thiên hướng của người tham gia phản hồi
- Lựa chọn các ví dụ để huấn luyện mô hình
Nắm được những ưu nhược điểm này sẽ giúp chúng ta áp dụng RLHF một cách hiệu quả nhất.
Tương lai của RLHF
Sẽ không quá bất ngờ nếu RLHF sẽ lọt vào top trending của cộng đồng nghiên cứu trong những năm tới. Phương pháp này đã chứng minh được hiệu quả (đáng kinh ngạc) khi được dùng để xây dựng ChatGPT. Liệu ứng dụng của RLHF có mọc lên như nấm sau mưa? Chúng ta hãy cùng chờ xem!
Tham khảo
- How ChatGPT actually works
- Aligning language models to follow instructions
- Understanding Reinforcement Learning from Human Feedback
- Training language models to follow instructions with human feedback
- RLHF: Reinforcement Learning from Human Feedback
- Deep Reinforcement Learning course
- GPT-4 vs ChatGPT

Leave a comment