
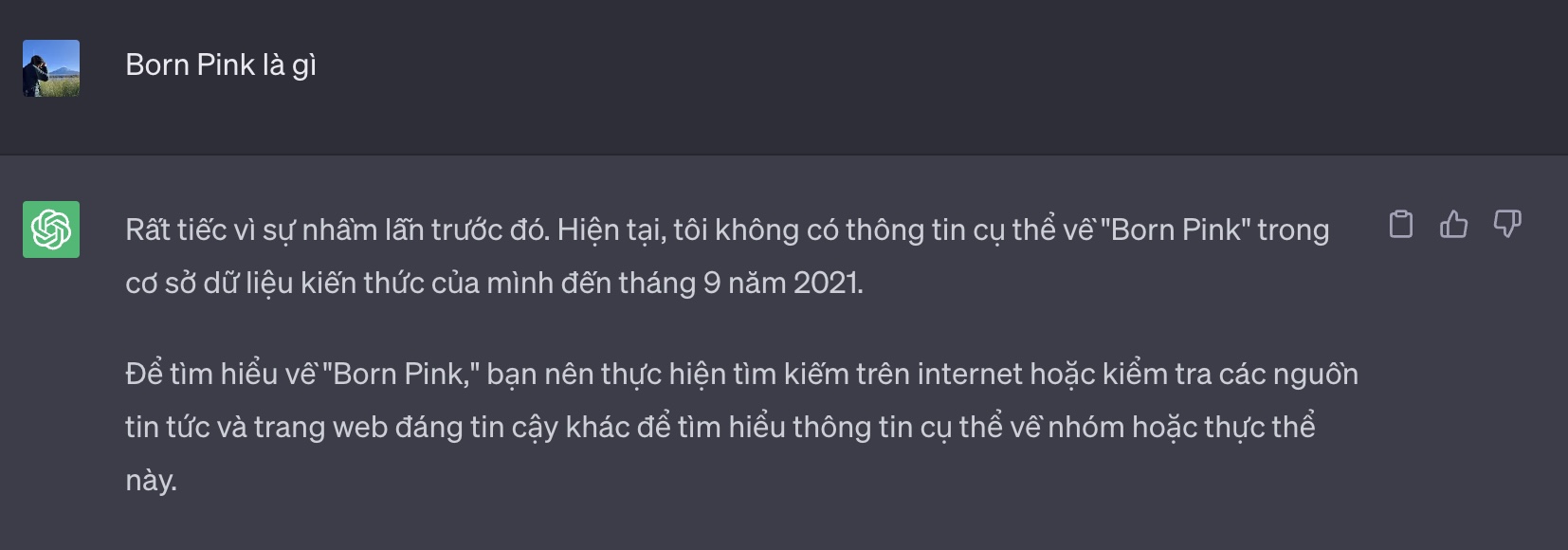
Mặc dù là chatbot tốt nhất hiện tại, ChatGPT không thể trả lời về những thông tin mà nó chưa được tiếp xúc trong quá trình huấn luyện.
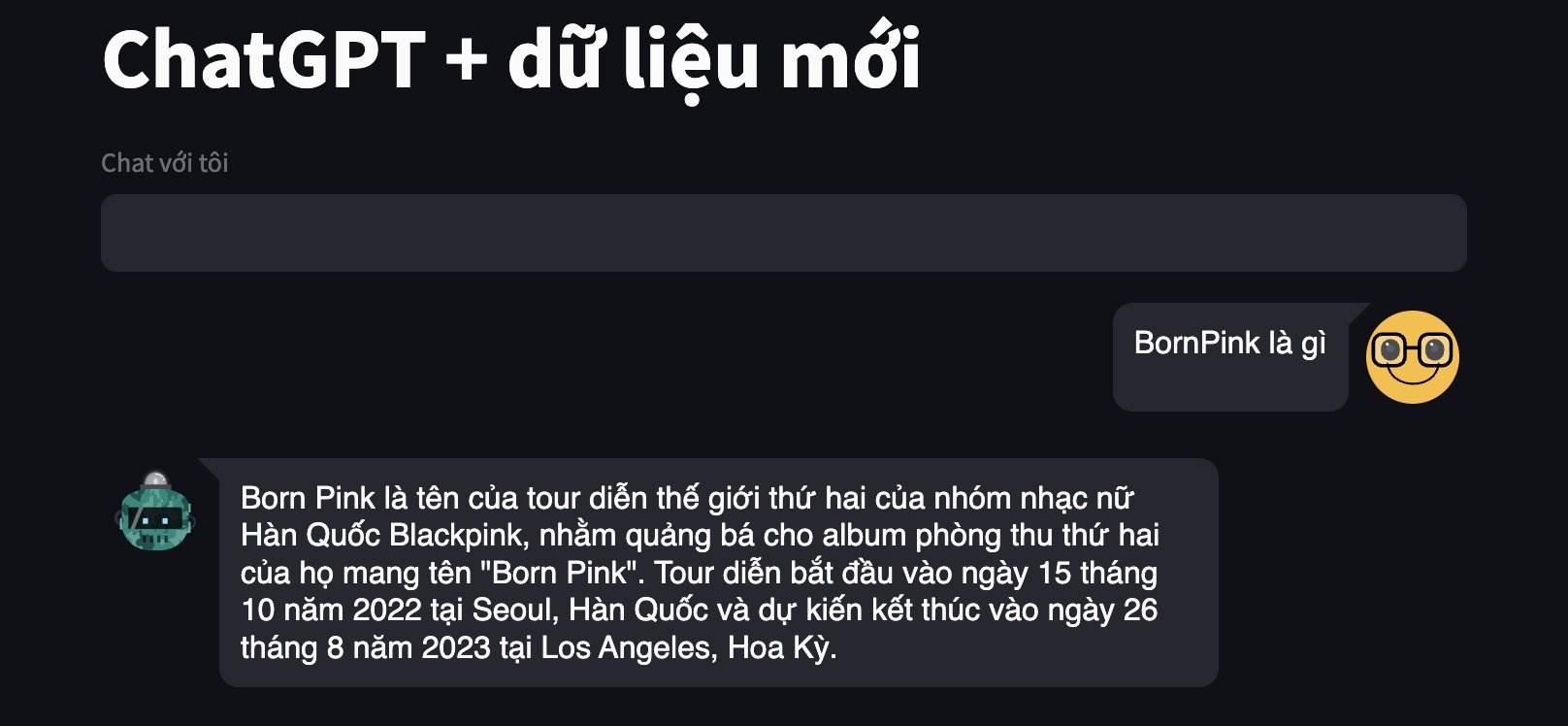
Dưới đây là một ví dụ khi mình hỏi ChatGPT về chuyến lưu diễn Born Pink của nhóm nhạc Black Pink (nhân dịp gần đây đang hot về chủ đề này khi có chương trình biểu diễn ở Hà Nội). ChatGPT không hề biết về thông tin này và chỉ có thể gợi ý chúng ta tìm kiếm thêm trên internet.
Khả năng trả lời xoay quanh thông tin mới cũng có rất nhiều ứng dụng, ví dụ như doanh nghiệp muốn xây dựng trợ lý ảo với khả năng trả lời về thông tin sản phẩm và dịch vụ của riêng họ.
Vậy liệu có cách nào để nạp thêm kiến thức cho ChatGPT? Trong bài hôm nay, hãy cùng thử bổ sung kiến thức cho ChatGPT để xây dựng một chatbot mới.
Retrieval Augmented Generation (RAG)
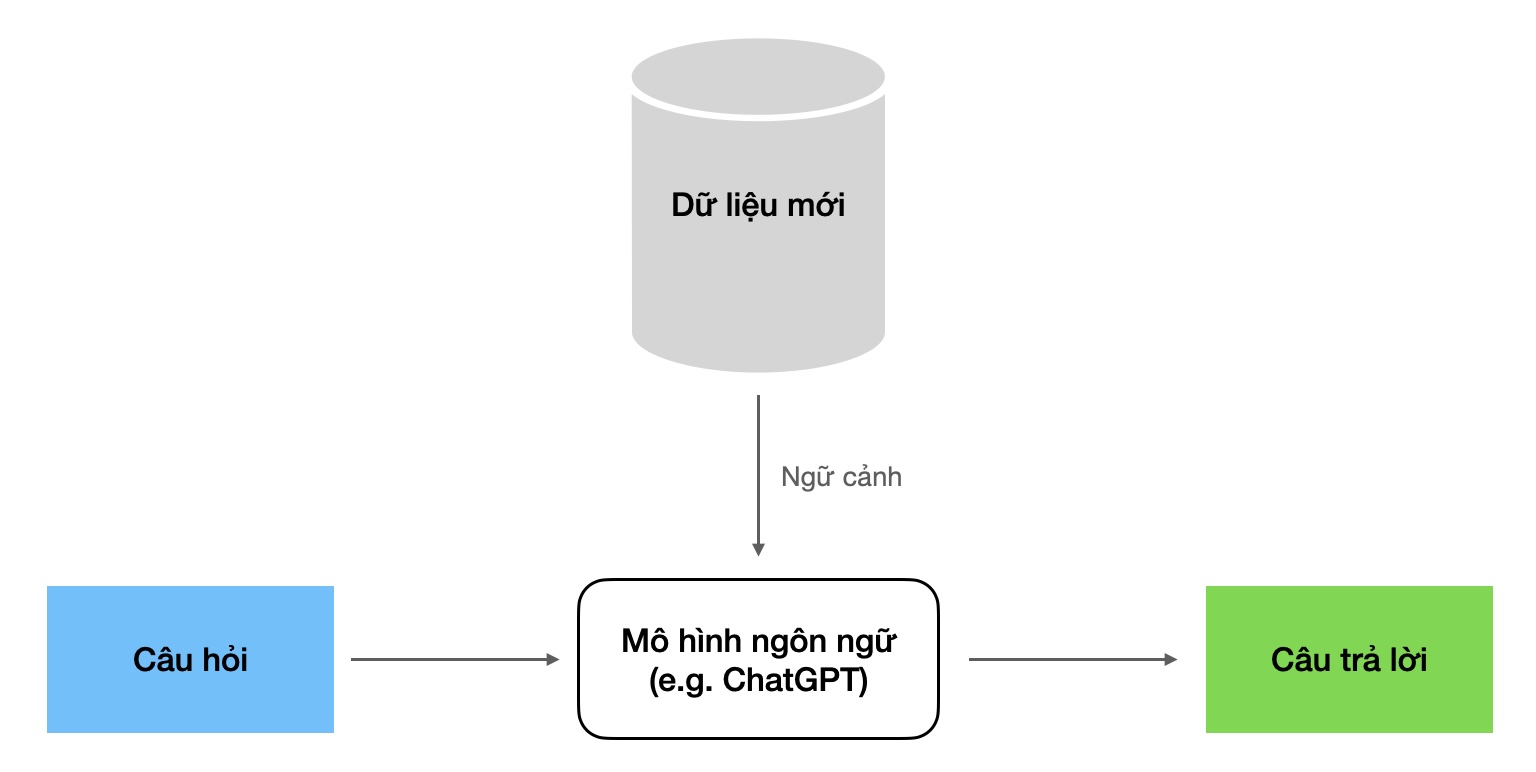
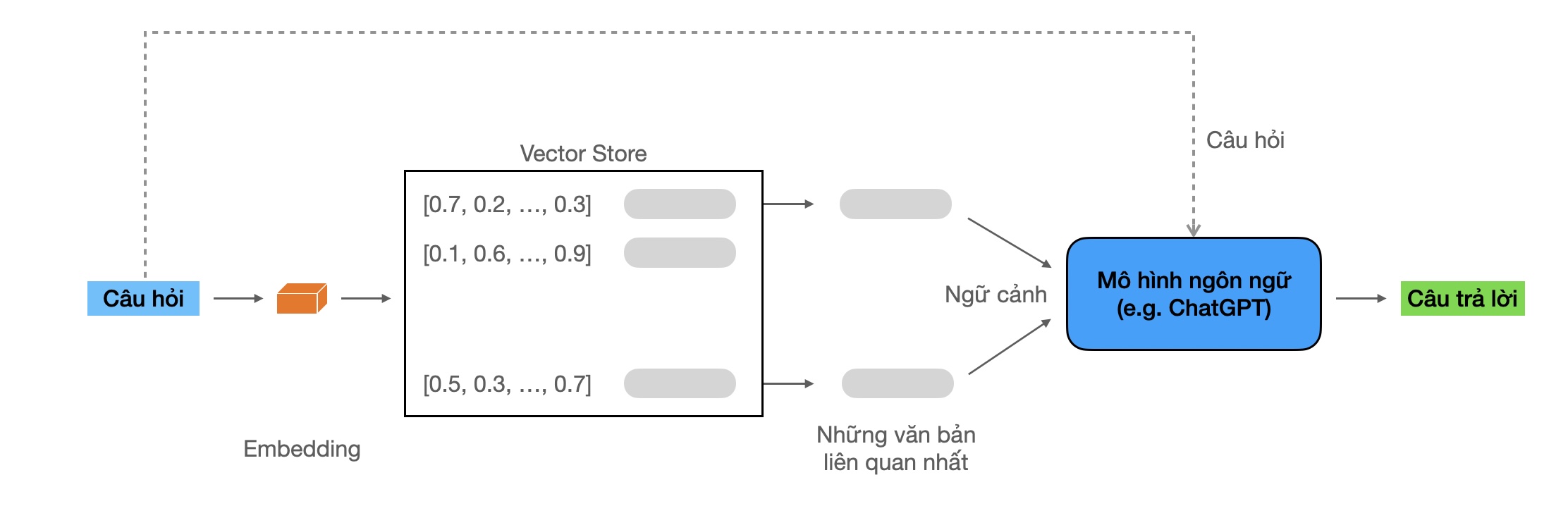
Để xây dựng dạng chatbot này, một kỹ thuật hay được dùng là Retrieval-augmented generation (RAG). Đây là kỹ thuật giúp cải thiện chất lượng của chatbot bằng cách sử dụng dữ liệu sẵn có với vai trò ngữ cảnh để những câu trả lời chính xác, hợp lý hơn.
Thực hành
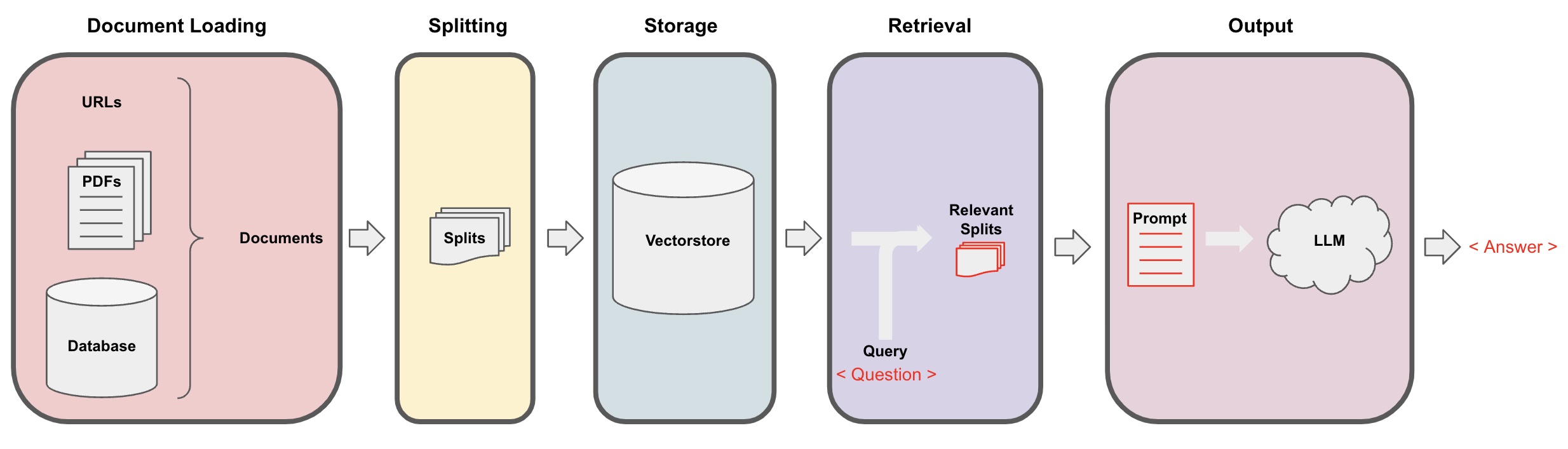
Bài thực hành hôm nay sẽ xây dựng một chatbot với các bước cơ bản như sau:
- (1) Document Loading (đọc dữ liệu): dữ liệu đầu vào có thể đến từ nhiều nguồn và ở nhiều định dạng khác nhau.
- (2) Document Splitting (chia nhỏ dữ liệu): các mô hình ngôn ngữ thường có giới hạn về đơn vị từ nó có thể xử lý (token limit), do đó dữ liệu cần được chia nhỏ để tránh lỗi về giới hạn này.
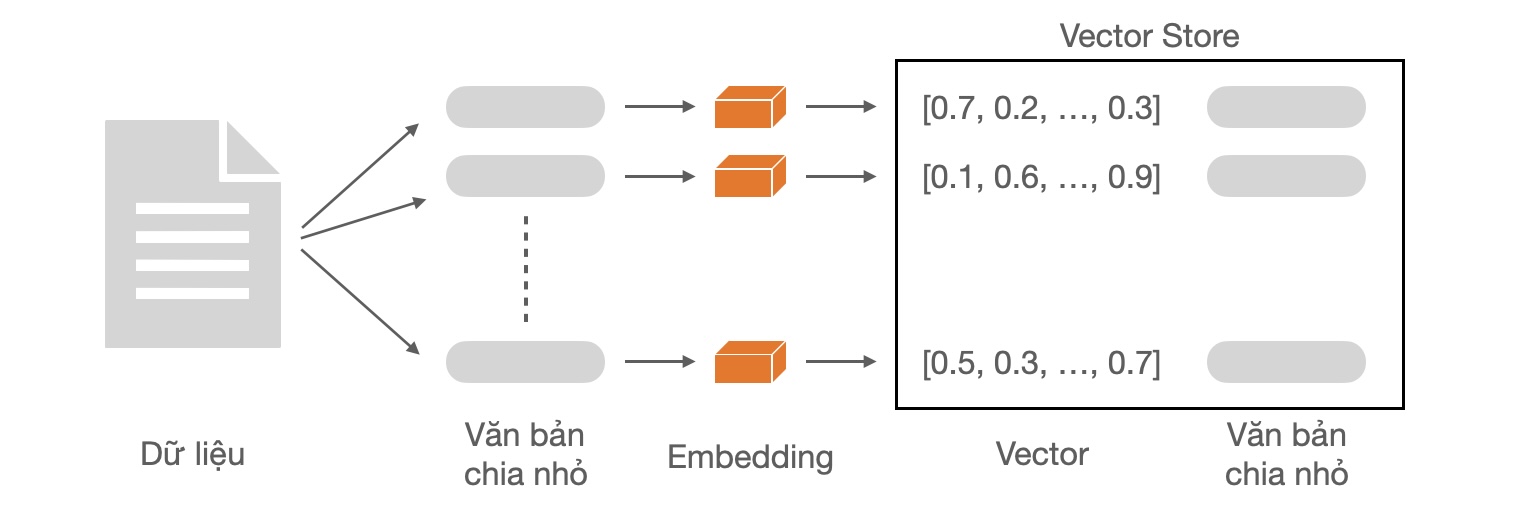
- (3) Storage (lưu trữ): sau khi được chia nhỏ, dữ liệu văn bản sẽ được biểu diện dưới dạng số (embedding vectors) và lưu lại cơ sở dữ liệu (vector store thường được dùng để tối ưu cho việc tìm và trích xuất các vector tương tự).
- (4) Retrieval (trích xuất): dựa vào câu hỏi đầu vào, trích xuất những văn bản có liên quan.
- (5) Output (trả lời): dùng mô hình ngôn ngữ để trả lời câu hỏi với ngữ cảnh là thông tin từ những văn bản trích xuất từ bước (4).
Cấu trúc code
Mã nguồn được dùng trong bài hôm nay được lưu tại Panda ML Github để tiện cho việc tham khảo. Cấu trúc code cụ thể như sau:
.
├── born_pink_world_tour.md
├── chat_with_your_data.py
└── data_to_vectordb.py
- File
born_pink_world_tour.mdlà file markdown chứa thông tin về Born Pink World Tour, được dùng như file dữ liệu mới
# Born Pink World Tour
Born Pink World Tour is the ongoing second worldwide concert ...
- File
chat_with_your_data.pylà file để chạy chatbot, phụ trách chính cho phần Retrieval và Output - File
data_to_vectordb.pyphụ trách phần Document Loading, Document Splitting và Storage
Với dữ liệu mới, trước tiên chúng ta cần lưu dữ liệu này vào cơ sở dữ liệu
python data_to_vectordb.py
Sau đó, chúng ta có thể khởi động chatbot với đoạn code dưới đây:
streamlit run chat_with_your_data.py
Nội dung code
data_to_vectordb.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# (1) Document Loading
loader = TextLoader("./born_pink_world_tour.md")
docs = loader.load()
# (2) Document Splitting
chunk_size = 150
chunk_overlap = 0
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "(?<=\. )", " ", ""],
)
split_docs = text_splitter.split_documents(docs)
# (3) Store document and embeddings to vector store
embedding = OpenAIEmbeddings()
vectordb = FAISS.from_documents(
documents=split_docs,
embedding=embedding,
)
DATA_STORE_DIR = "data_store"
vectordb.save_local(DATA_STORE_DIR)
- Dòng 1 - 3: đọc dữ liệu từ file markdown với
TextLoader. Ở đây chúng ta làm việc với file ở trên máy, còn nhiều loại định dạng khác như web, pdf, … - Dòng 5 - 13: chia nhỏ dữ liệu với
RecursiveCharacterTextSplitter. Ở đây, chúng ta chia nhỏ văn bản thành nhóm các câu có số lượng ký tự tối đa là 150.chunk_size: số ký tự tối đa cho một văn bản.chunk_overlap: số ký tự trùng nhau tối đa giữa 2 văn bản.separators: các ký tự dùng để chia nhỏ văn bản.
- Dòng 15 - 22: lưu dữ liệu vào vector store với FAISS (Facebook AI Similarity Search)
chat_with_your_data.py
1
2
3
4
5
6
7
8
# load db that store new data
DATA_STORE_DIR = "data_store"
vectordb = FAISS.load_local(DATA_STORE_DIR, embeddings=OpenAIEmbeddings())
# initialize language model and question & answer retrieval from langchain
llm = ChatOpenAI(temperature=0.0)
qa_stuff = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=vectordb.as_retriever()
)
- Dòng 1 - 3: khởi tạo vector store từ file đã lưu ở bước trên với
FAISS.load_local. - Dòng 5: khởi tạo mô hình ngôn ngữ
ChatOpenAI - Dòng 6 - 8: khởi tạo mô hình trả
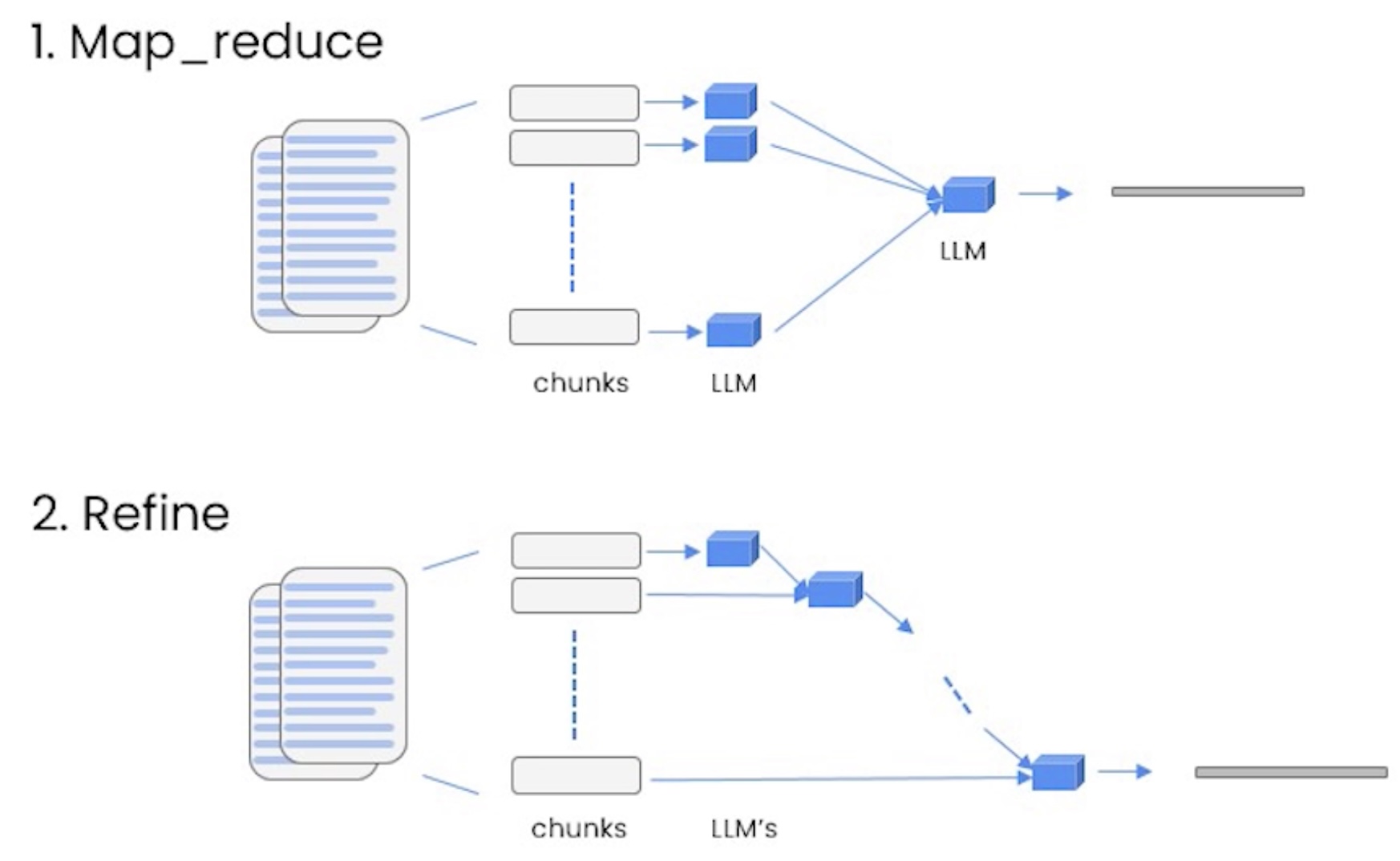
RetrievalQA(trích xuất thông tin liên quan và dùng mô hình ngôn ngữ để trả lời). Trong đó:retrieversẽ phụ trách nhiệm vụ tìm những văn bản liên quanllmphụ trách nhiệm vụ trả lời dựa trên những văn bản nàychain_typecách sử dụng các văn bản liên quan làm ngữ cảnh cho mô hình ngôn ngữ.chain_type=stuffnghĩa là sử dụng trực tiếp tất cả các văn bản liên quan, phương pháp này phù hợp cho những đoạn văn bản nhỏ, còn với số lượng văn bản lớn hơn chúng ta nên dùng phương pháp khác nhưmap_reducevàrefine.
Mã nguồn
Kết quả
Sau khi cập nhật kiến thức về chuyến lưu diễn Born Pink, giờ đây Chatbot đã có thể tìm kiếm thông tin và trả lời về chủ đề này.
Tạm kết
Dựa trên kỹ thuật Retrieval Augmented Generation, chúng ta đã xây dựng được một chatbot mới “hiểu biết hơn cả ChatGPT”. Quả thực mình rất ấn tượng với khả năng dung nạp thông tin của mô hình ngôn ngữ nói chung và của ChatGPT nói riêng. Giờ đây, chúng ta có thể bổ sung thêm kiến thức cho Chatbot trong bất cứ một chủ đề mới nào và cho phép người dùng tương tác với thông tin mới một cách dễ dàng.
Các bạn hãy thử với tập dữ liệu của mình xem? Kết quả ảo lắm :)

Leave a comment