
Trong bài hôm nay, chúng ta sẽ học 3 phương pháp để xử lý dữ liệu bị thiếu (missing values) và so sánh hiệu quả của các phương pháp này với nhau.
Giới thiệu
Trên thực tế, dữ liệu của chúng ta rất hay bị thiếu dữ liệu. Ví dụ như với tập dữ liệu về giá nhà, dữ liệu có thể bị thiếu trong những trường hợp sau:
- Ngôi nhà với 2 phòng ngủ không thể có dữ liệu cho phòng ngủ thứ 3
- Chủ ngôi nhà không cung cấp đủ thông tin khi được khảo sát
Hầu hết các thư viện học máy đều gặp phải lỗi khi xây dựng mô hình mà dữ liệu bị thiếu. Do đó, chúng ta cần một số phương pháp để xử lý vấn đề này.
3 phương pháp
1 - Bỏ các cột với dữ liệu bị thiếu (drop columns)
Cách xử lý đơn giản nhất là bỏ các cột bị thiếu giá trị.

Tuy đơn giản nhưng phương pháp có thể vô tình lược bỏ đi những thông tin quan trọng. Lấy ví dụ một tập dữ liệu với 10000 dòng, một đặc trưng quan trọng có duy nhất một giá trị bị thiếu. Phương pháp này sẽ lược bỏ đi đặc trưng này khỏi quá trình huấn luyện.
2 - Thay thế dữ liệu bị thiếu (imputation)
Đây là phương pháp “điền vào chỗ trống”, tức là tìm cách gán giá trị nào đó cho những phần bị thiếu. Ví dụ như dùng giá trị trung bình của cột dữ liệu để thay vào phần bị thiếu.
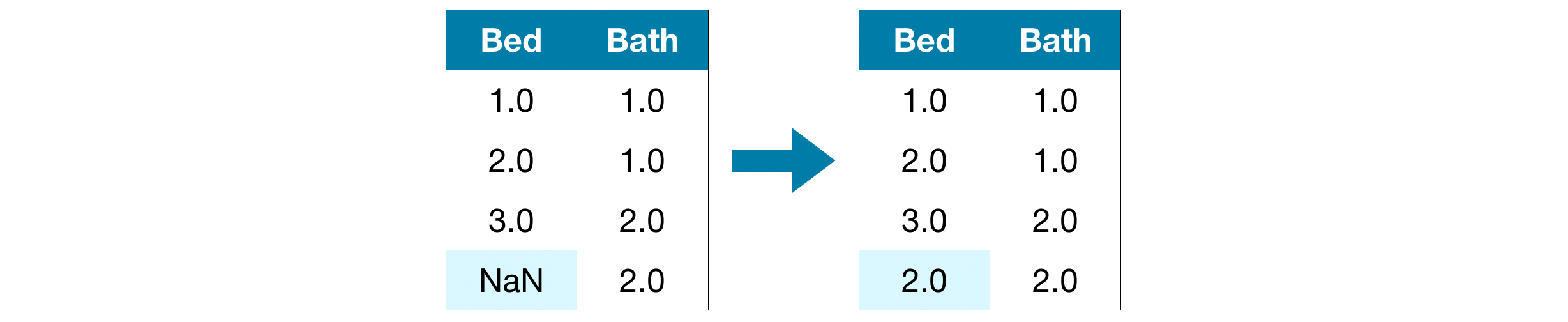
Những giá trị được dùng tuy có thể không chính xác, nhưng phương pháp này thường cho chúng ta mô hình chính xác hơn phương pháp lược bỏ cột dữ liệu nói trên.
3 - Thay thế giá trị bị thiếu mở rộng (extended imputation)
Phương pháp thay thế giá trị bị thiếu thường cho kết quả tương đối tốt. Tuy nhiên, những giá trị được gán có thể cao hơn hoặc thấp hơn giá trị thực tế. Hoặc đôi khi, những giá trị bị thiếu này lại chứa một tín hiệu quan trọng nào đó.
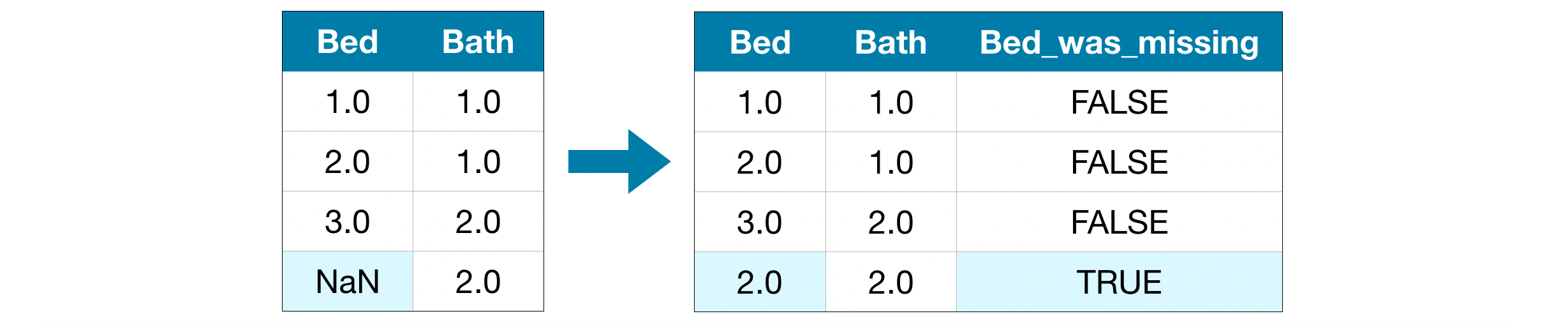
Trong những trường hợp này, sẽ tốt hơn nếu chúng ta giữ lại thông tin này bằng cách vào các cột thông tin về dòng dữ liệu bị thiếu. Mỗi một cột bị thiếu sẽ tương ứng với 2 cột dữ liệu mới:
- Một cột được gán các giá trị bị thiếu
- Một cột chứa thông tin dòng nào bị thiếu dữ liệu trong dữ liệu gốc
Tuỳ từng trường hợp, phương pháp này có thể cải thiện độ chính xác của mô hình. Do đó, chúng ta nên thử các phương pháp khác nhau để chọn ra cách tốt nhất cho bài toán của mình.
Thực hành
Bài thực hành hôm nay sử dụng dữ liệu về giá nhà tại Melbourne, Úc. Mô hình của chúng ta sẽ sử dụng các đặc trưng như số phòng và diện tích đất để dự đoán giá nhà.
Hãy bắt đầu bằng việc đọc dữ liệu và chia dữ liệu thành tập huấn luyện và tập điểm định (training & validation data): X_train, X_valid, y_train, y_valid.
import pandas as pd
from sklearn.model_selection import train_test_split
# Đọc dữ liệu
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Chọn biến mục tiêu
y = data.Price
# Để đơn giản, chỉ chọn các biến số học làm đặc trưng
melb_predictors = data.drop(['Price'], axis=1)
X = melb_predictors.select_dtypes(exclude=['object'])
# Chia dữ liêu làm tập huấn luyện và kiểm định
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
Định nghĩa hàm đánh giá chỉ số score_dataset() để so sánh các phương pháp khác nhau. Hàm này dùng sai số tuyệt đối trung bình (Mean Absolute Error - MAE) dựa trên mô hình rừng ngẫu nhiên (Random Forest).
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Hàm so sánh các phương pháp khác nhau
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)
Phương pháp 1
Do chúng ta có cả tập huấn luyện và kiểm định, chúng ta cần loại bỏ các cột giống nhau trên cả 2 tập dữ liệu này.
# Lấy danh sách các cột với dữ liệu bị thiếu từ toàn bộ dữ liệu
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# Bỏ các cột này từ tập huấn luyện và kiểm định
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE cho phương pháp 1 (bỏ các cột bị thiếu dữ liệu):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))
# 183550.22137772635
Phương pháp 2
Với phương pháp này, chúng ta hãy thử thay các giá trị bị thiếu bằng giá trị trung bình của mỗi cột.
Tuy đơn giản, dùng giá trị trung bình thường hoạt động tương đối tốt (tất nhiên còn tuỳ bài toán và dữ liệu khác nhau). Các chuyên gia thống kê phát minh ra nhiều cách phức tạp hơn để xác định giá trị thay thế (dùng hồi quy tuyến tính là một ví dụ), tuy nhiên các phương pháp này thường cho kết quả không quá vượt trội nếu kết hợp với những mô hình học máy phức tạp hơn.
from sklearn.impute import SimpleImputer
# Thay thế giá trị bị thiếu
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# Đặt lại tên các cột
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE cho phương pháp 2 (Thay thế giá trị bị thiếu):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))
# 178166.46269899711
Chúng ta có thể thấy MAE của phương pháp 2 nhỏ hơn phương pháp 1, phương pháp 2 hoạt động tốt hơn trên tập dữ liệu này.
Phương pháp 3: Thay thế mở rộng
Tiếp theo chúng ta sẽ thay thế giá trị bị thiếu, đồng thời giữ lại thông tin giá trị nào đã được thay thế.
# Lập bản sao dữ liệu để tránh thay đổi dữ liệu gốc
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# Tạo các cột mới để lưu thông tin dòng nào bị thiếu dữ liệu
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Thay thế dữ liệu
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Đặt lại tên các cột
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE cho phương pháp 3 (Thay thế mở rộng):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))
# 178927.503183954
Phương pháp này cho kết quả kém hơn một chút so với phương pháp 2.
Tại sao thay thế dữ liệu tốt hơn là lược bỏ dữ liệu
Tập huấn luyện có 10864 dòng và 12 cột, trong đó 3 cột bị thiếu dữ liệu. Với mỗi cột này, chưa đến một nửa dữ liệu bị thiếu. Do đó, loại bỏ các cột đã vô tình bỏ đi rất nhiều thông tin hữu ích trong trường hợp này.
# Kích thước dữ liệu (số dòng * số cột)
print(X_train.shape)
# Số lượng dữ liệu bị thiếu cho từng cột
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])
# (10864, 12)
# Car 49
# BuildingArea 5156
# YearBuilt 4307
Kết luận
Bài hôm nay giới thiệu đến các bạn một số phương pháp để xử lý dữ liệu bị thiếu. Các bạn hãy thử áp dụng cho cuộc thi dự đoán giá nhà cho người dùng của Kaggle Learn và gửi dự đoán của mình xem sao.
Bạn có thể dùng Kaggle notebook ở đây để thực hành. Happy learning!

Leave a comment