
Trong bài hôm nay, chúng ta sẽ học một khái niệm mới về biến phân loại (categorical variables) cùng với cách xử lý loại dữ liệu này.
Giới thiệu
Biến phân loại giúp cho việc phân chia dữ liệu vào các nhóm khác nhau với số nhóm có giá trị nhất định. Dưới đây là một vài ví dụ:
- Một khảo sát về mức độ ăn sáng với 4 lựa chọn: “Không ăn sáng”, “Thỉnh thoảng”, “Hầu hết sẽ ăn”, “Ăn thường xuyên”. Trong trường hợp này, dữ liệu sẽ thuộc dạng phân loại, vì các câu trả lời luôn nằm trong 4 nhóm trên.
- Một khảo sát về hãng ô tô mà mọi người sở hữu, câu trả lời có thể là “Honda”, “Toyota” hay “Ford”… dữ liệu trong trường hợp này cũng là biến phân loại.
Trên thực tế, dữ liệu của chúng ta thường đều chứa biến phân loại. Tuy nhiên, hầu hết các mô hình học máy đều chỉ làm việc được với biến số học, do đó chúng ta sẽ gặp phải lỗi nếu không xử lý biến phân loại trước khi đưa vào việc huấn luyện mô hình. Có nhiều cách để làm việc với biến phân loại, trong bài hôm nay chúng ta sẽ làm quen với 3 phương pháp dưới đây.
3 phương pháp xử lý biến phân loại
1 - Loại bỏ biến phân loại
Đây là cách dễ nhất, không biết xử lý ra sao thì chúng ta không xử lý nữa mà loại bỏ luôn các biến này. Phương pháp này chỉ hiệu quả nếu các biến phân loại không chứa thông tin nào hữu ích.
2 - Mã hoá thứ tự (ordinal encoding)
Mã hoá thứ tự là phương pháp gắn cho mỗi giá trị phân loại một giá trị số tự nhiên tương ứng.
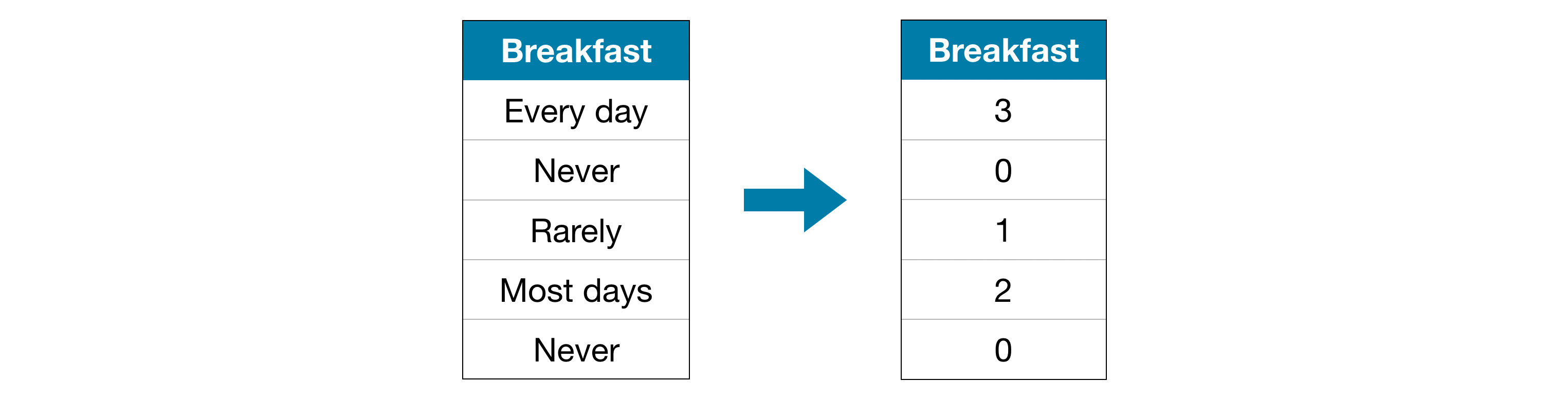
Phương pháp này giả định thứ tự giữa các giá trị trong biến phân loại: "Never" (0) < "Rarely" (1) < "Most days" (2) < "Every day" (3).
Giả định này có vẻ đúng cho ví dụ trên đây vì mỗi giá trị tương ứng với mức độ thường xuyên cửa việc ăn sáng. Khi giá trị trong biến phân loại có thứ tự nhất định, chúng được gọi là biến thứ tự (ordinal variables). Lưu ý rằng không phải biến phân loại nào mà các giá trị có thể so sánh với nhau nên chúng ta cần cẩn thận khi sử dụng. Đối với những mô hình dạng cây (tree-based models) như cây quyết định và rừng ngẫu nhiên, thông thường phương pháp này sẽ hoạt động tương đối tốt.
3 - Mã hoá One-hot (one-hot encoding)
Mã hoá one-hot tạo những cột mới để chỉ ra sự hiện diện của từng giá trị trong dữ liệu gốc. Để cho dễ hiểu, hãy tham khảo ví dụ sau.
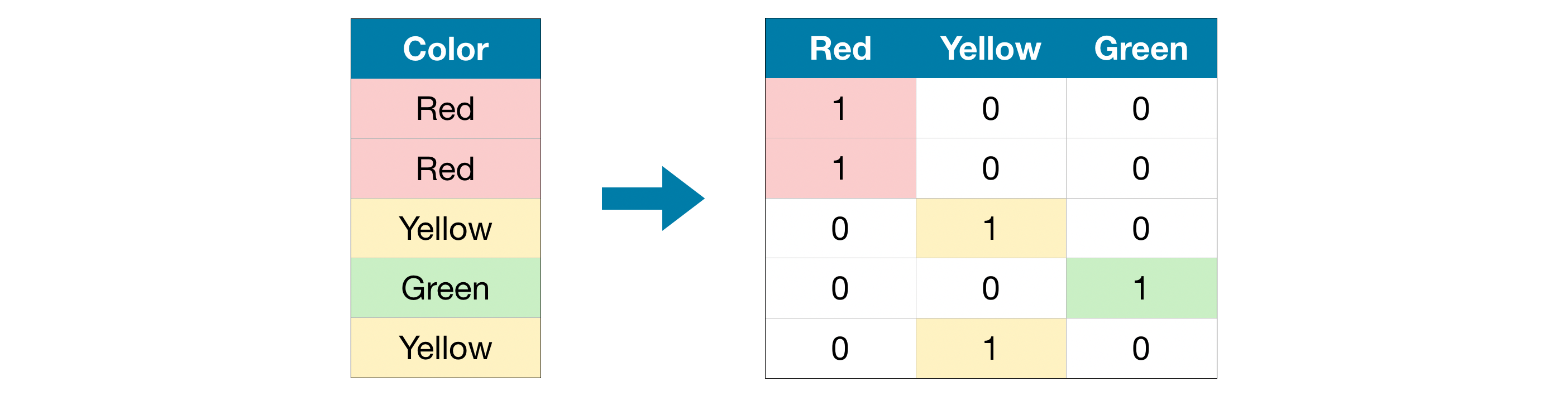
Trong dữ liệu của chúng ta, “Color” là biến phân loại với 3 nhóm: “Red”, “Yellow”, và “Green”. Mã hoá one-hot sẽ bao gồm 3 cột dữ liệu (mỗi cột tương ứng với 1 nhóm). Nếu giá trị của biến “Color” là “Red” chúng ta đặt giá trị 1 trong cột “Red”; nếu giá trị là “Yellow” chúng ta đặt giá trị 1 trong cột “Yellow”,…
Khác với mã hoá thứ tự, mà hoá one-hot không giả định thứ tự cho biến phân loại. Do đó, phương pháp này sẽ hoạt động tốt với những biến phân loại không có tính thứ tự rõ ràng (“Red” không có ý nghĩa lớn hơn hay nhỏ hơn so với “Yellow”). Những biến không có tính thứ tự giữa các nhóm còn được gọi là nominal variables (biến danh nghĩa?).
Mã hoá one-hot thường hoạt động không tốt khi biến phân loại có quá nhiều giá trị khác nhau (bạn thường không nên dùng phương pháp này nếu có nhiều hơn 15 nhóm trong biến phân loại).
Thực hành
Bài thực hành hôm nay sử dụng dữ liệu về giá nhà tại Melbourne, Úc. Mô hình của chúng ta sẽ sử dụng các đặc trưng như số phòng và diện tích đất để dự đoán giá nhà.
Hãy bắt đầu bằng việc đọc dữ liệu và chia dữ liệu thành tập huấn luyện và tập điểm định (training & validation data): X_train, X_valid, y_train, y_valid.
import pandas as pd
from sklearn.model_selection import train_test_split
# Đọc dữ liệu
data = pd.read_csv('../input/melbourne-housing-snapshot/melb_data.csv')
# Chọn biến mục tiêu và đặc trưng
y = data.Price
X = data.drop(['Price'], axis=1)
# Chia dữ liêu làm tập huấn luyện và kiểm định
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
# Bỏ các cột bị thiếu dữ liệu
cols_with_missing = [col for col in X_train_full.columns if X_train_full[col].isnull().any()]
X_train_full.drop(cols_with_missing, axis=1, inplace=True)
X_valid_full.drop(cols_with_missing, axis=1, inplace=True)
# Chọn các biến phân loại với ít nhóm trong mỗi biến (low cardinality)
low_cardinality_cols = [
cname for cname in X_train_full.columns
if X_train_full[cname].nunique() < 10
and X_train_full[cname].dtype == "object"
]
# Chọn các biến số học
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
# Chỉ giữ các biến đã được chọn
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
Tiếp theo, chúng ta sẽ liệt kê tất cả các biến phân loại. Chúng ta có thể sử dụng kiểu dữ liệu (đặc trưng dtype) của từng cột. Kiểu dữ liệu object chỉ ra rằng cột dữ liệu thuộc dạng văn bản (text). Không phải lúc nào dữ liệu văn bản cũng là biến phân loại, nhưng trong trường hợp của chúng ta thì đúng như vậy.
# Lấy danh sách các biến phân loại
s = (X_train.dtypes == 'object')
object_cols = list(s[s].index)
print("Categorical variables:")
print(object_cols)
# ['Type', 'Method', 'Regionname']
Hàm đánh giá chất lượng
Định nghĩa hàm đánh giá chỉ số score_dataset() để so sánh các phương pháp khác nhau. Hàm này dùng sai số tuyệt đối trung bình (Mean Absolute Error - MAE) dựa trên mô hình rừng ngẫu nhiên (Random Forest).
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# Hàm so sánh các phương pháp khác nhau
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)
Phương pháp 1 (loại bỏ dữ liệu)
Chúng ta có thể loại bỏ các biến phân loại bằng hàm select_dtypes().
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
# 175703.48185157913
Phương pháp 2 (mã hoá thứ tự)
Thư viện Scikit-learn có lớp OrdinalEncoder để áp dụng mã hoá thứ tự.
from sklearn.preprocessing import OrdinalEncoder
# Lập bản sao dữ liệu để tránh thay đổi dữ liệu gốc
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()
# Áp dụng mã hoá thứ tự cho từng biến phân loại
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
# 165936.40548390493
Trong đoạn code trên, chúng ta gán một giá trị ngẫu nhiên cho mỗi nhóm trong biến phân loại. Đây là một phương pháp đơn giản thường được sử dụng, tuy nhiên chúng ta sẽ có thể đạt được độ chính xác cao hơn một chút nếu chúng ta tìm hiểu dữ liệu và điều chỉnh các giá trị cho phù hợp với trật tự thực tế (nếu có).
Phương pháp 3 (mã hoá one-hot)
Chúng ta sẽ dùng OnehotEncoder trong scikit-learn để áp dụng mã hoá one-hot. Có các tham số có thể được tinh chỉnh:
handle_unknown='ignore'để tránh lỗi nếu tập dữ liệu kiểm định chứa các nhóm mới, chưa xuất hiện trong tập huấn luyệnsparse=Falseđể đảm bảo dữ liệu mã hoá ở dạng numpy array thay vì dạng matrận sparse.
Để dùng mã hoá này, chúng ta chỉ cần cung cấp các cột dữ liệu chứa biến phân loại.
from sklearn.preprocessing import OneHotEncoder
# Áp dụng mã hoá one-hot cho các cột chứa biến phân loại
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))
# Mã hoá one-hot loại bỏ index, One-hot encoding removed index; put it back
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index
# Loại bỏ các biến phân loại
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)
# Thay thế bằng mã hoá one-hot
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)
# Đảm bảo rằng tên các cột ở dạng string
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
# 166089.4893009678
Phương pháp nào tốt nhất
Trong ví dụ của chúng ta, loại bỏ các biến hoạt động kém nhất (phương pháp 1). Phương pháp 2 cho sai số nhỏ nhất nhưng khác biệt không quá nhiều so với phương pháp 3.
Trong thực tiện, mã hoá one-hot thường cho kết quả tốt nhất nhưng cũng còn tuỳ vào bài toán và dự liệu cụ thể.
Kết luận
Sau bài hôm nay, hy vọng rằng các bạn sẽ trở thành một nhà khoa học dữ liệu toàn diện hơn với các phương pháp xử lý dữ liệu với biến phân loại. Các bạn hãy thử áp dụng cho cuộc thi dự đoán giá nhà cho người dùng của Kaggle Learn và gửi dự đoán của mình xem sao.
Bạn có thể dùng Kaggle notebook ở đây để thực hành. Happy learning!

Leave a comment