
Bài hôm nay, chúng ta sẽ tìm hiểu về khái niệm overfitting và underfitting và cách áp dụng để cải thiện độ chính xác của mô hình.
Thử nghiệm với nhiều mô hình khác nhau
Với những bài trước, bạn đã có phương pháp để xây dựng mô hình và đánh giá chất lượng của chúng. Bạn có thể thử nghiệm với bất cứ mô hình nào và xem mô hình nào có khả năng dự đoán tốt nhất. Vậy bạn sẽ lựa chọn mô hình nào khác?
Với mô hình cây quyết định, bạn có thể tham khảo tài liệu của thư viện scikit-learn để thấy rằng có rất nhiều tham số có thể thay đổi (thậm chí là quá nhiều). Trong số đó, một tham số quan trọng là độ sâu của cây. Mô hình có độ sâu lớn tương ứng với nhiều phân nhánh (splits), cũng tức là bao gồm nhiều quy luật nhỏ hơn. Dưới đây là ví dụ về một mô hình tương đối nông với độ sâu bằng 2:
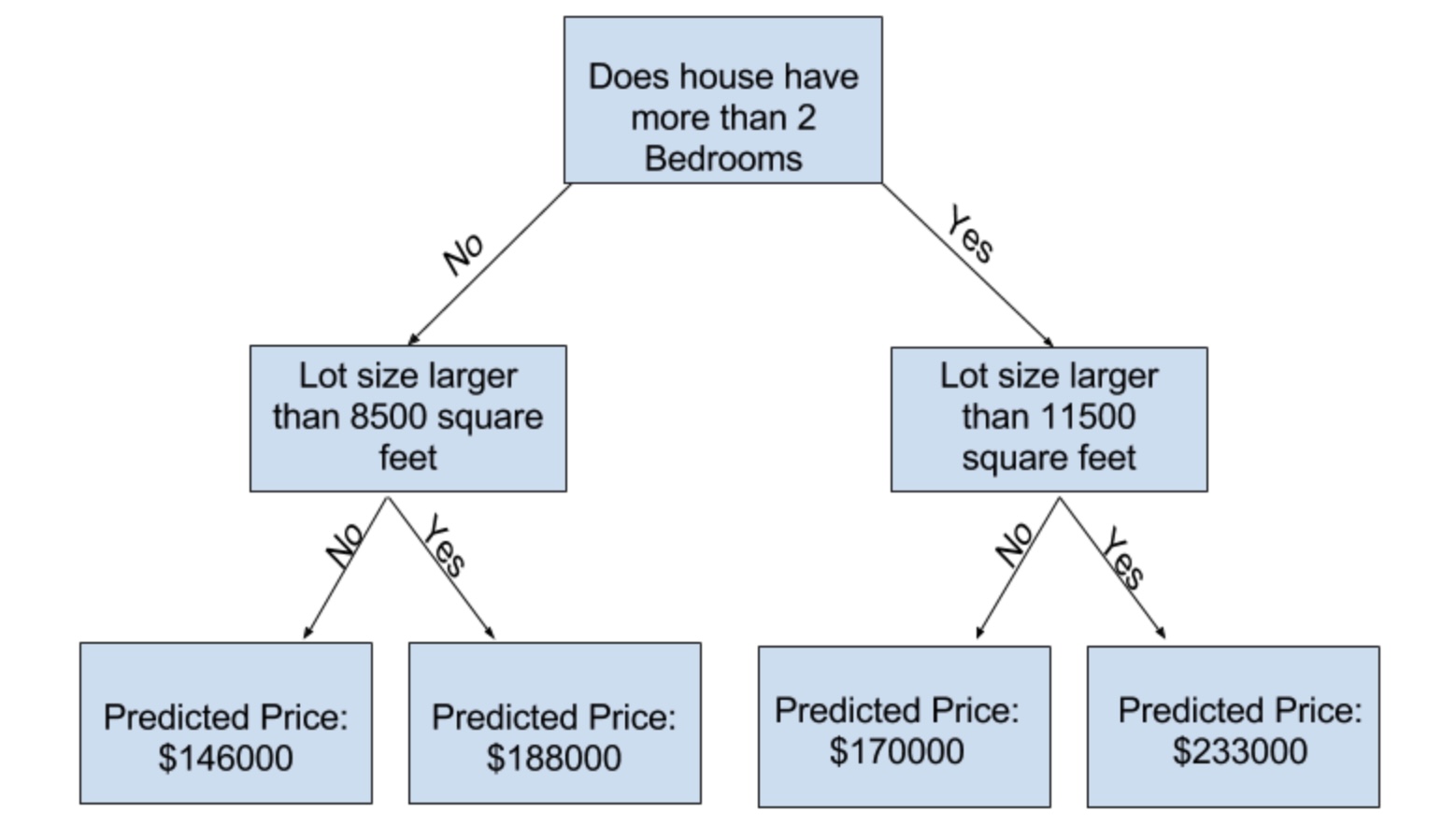
Trên thực tế, không quá khó để bắt gặp những mô hình 10 phân nhánh ở tầng sâu nhất. Cây có độ sâu càng cao, dữ liệu sẽ được chia thành nhiều nhóm nhỏ hơn. Nếu cây có 1 phân nhánh, dữ liệu sẽ được chia làm 2 nhóm. Nếu mỗi nhóm này tiếp tục phân nhánh, chúng ta sẽ có 4 nhóm tất cả. Cứ như vậy, số nhóm sẽ tăng lên theo cấp số nhân và chúng ta sẽ có 2 ^ 10 nhóm những ngôi nhà nếu chúng ta đến tầng thứ 10.
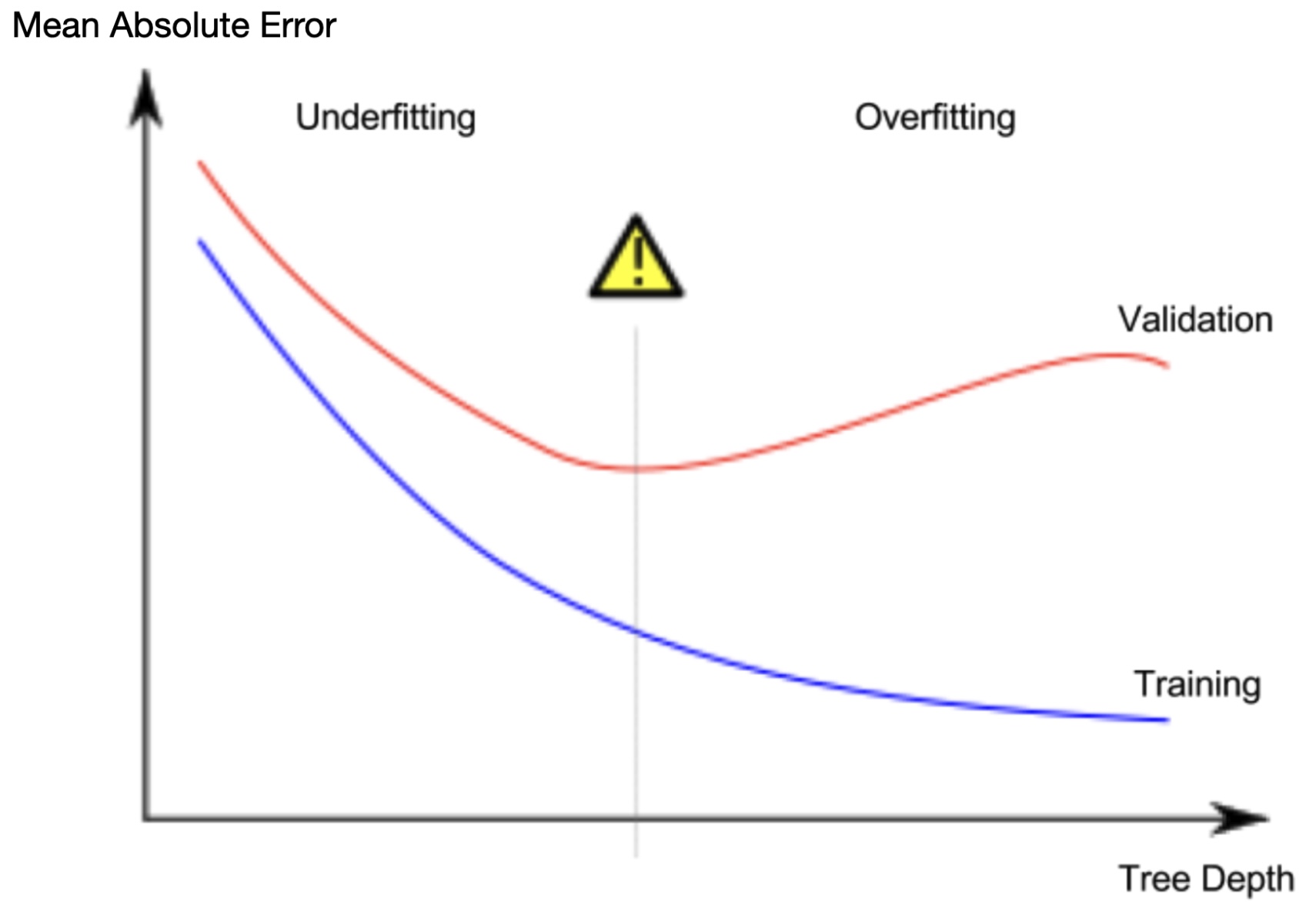
Với nhiều nhóm nhỏ, mỗi nhóm sẽ có ít ngôi nhà hơn. Mô hình có thể dự đoán giá nhà gần với giá trị thực tế của những ngôi nhà trong nhóm, nhưng rất có thể sẽ đưa ra dự đoán không chính xác cho những căn nhà mới (do mô hình chỉ dựa vào vài ngôi nhà để đưa ra dự đoán). Hiện tượng này gọi là overfitting, khi mô hình cho độ chính xác cao trên tập huấn luyện nhưng lại hoạt động kém trên tập dữ liệu mới.
Ngược lại, nếu cây quyết định của chúng ta quá nông, nó cũng không chia các ngôi nhà ra các nhóm có đặc điểm khác biệt. Lấy ví dụ trường hợp đặc biệt, nếu mô hình chỉ chia các ngôi nhà thành 2 hoặc 4 nhóm, mỗi nhóm vẫn có nhiều loại ngôi nhà. Kết quả dự đoán có thể sai lệch với hầu hết các ngôi nhà, kể cả trong tập huấn luyện. Khi mô hình không thể nắm bắt được quy luật tạo ra sự khác biệt trong dữ liệu, ngay cả trong tập dữ liệu huấn luyện, thì được gọi là underfitting.
Do chúng ta quan tâm đến độ chính xác trên dữ liệu mới, chúng ta cần cân bằng giứa underfitting và overfitting. Một cách trực quan, chúng ta muốn tìm vị trí mà chúng ta có sai số nhỏ nhất trên tập kiểm định.
Thực hành
Đối với mô hình cây quyết định, có nhiều tham số để thay đổi cấu trúc của cây. Ví dụ như tham số max_depth được dùng để kiểm soát độ sâu của cây. Hay tham số max_leaf_nodes kiểm soát số lượng nhóm tối đa. Do mô hình cho phép các nhánh có độ sâu khác nhau (cây có thể chỉ có 2 nhánh, 1 nhánh có độ sâu bằng 10, 1 nhánh có độ sâu bằng 1), chúng ta sẽ dùng max_leaf_nodes để kiểm soát vấn đề underfitting và overfitting.
Chúng ta có thể dùng hàm tiện lợi sau để so sánh sai số trung bình tuyệt đối khi sử dụng các giá trị max_leaf_nodes.
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
Dữ liệu chúng ta dùng được chia thành train_X, val_X, train_y, val_y giống bài trước:
import pandas as pd
# Đọc dữ liệu
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# Lọc bớt các dòng mà có giá trị bị thiếu
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Lựa chọn giá trị mục tiêu (y) và các đặc trưng (X)
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# chia dữ liệu thành tập huấn luyện và tập đánh giá (training_data & validation_data)
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
Tiếp đó, chúng ta có thể dùng vòng lặp for-loop để so sánh độ chính xác của các mô hình được xây dựng với các giá trị khác nhau của max_leaf_nodes.
# so sánh MAE với những giá trị khác nhau của max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
# kết quả
# Max leaf nodes: 5 Mean Absolute Error: 347380
# Max leaf nodes: 50 Mean Absolute Error: 258171
# Max leaf nodes: 500 Mean Absolute Error: 243495
# Max leaf nodes: 5000 Mean Absolute Error: 254983
Với kết quả trên, 500 là giá trị tối ưu của tham số max_leaf_nodes.
Tạm kết
Chúng ta có thể thấy mô hình sẽ có độ chính xác không cao trong trường hợp:
- Overfitting: tìm ra một quy luật ngẫu nhiên mà không lặp lại trên tập dữ liệu mới.
- Underfitting: không tìm ra quy luật quan trọng trong dữ liệu.
Để tránh gặp phải những vấn đề này, chúng ta có thể sử dụng tập kiểm định (validation data) để đánh giá độ chính xác của mô hình. Phương pháp này giúp chúng ta thử nghiệm được nhiều mô hình khác nhau và chọn ra những mô hình tốt nhất.

Leave a comment