
Gần đây có bạn hỏi mình nên chia dữ liệu làm mấy phần khi xây dựng mô hình học máy. Bạn đó đã tham khảo nhiều ví dụ và bài hướng dẫn nhưng có ví dụ thì chia làm 2 phần, trong khi ví dụ khác thì chia làm 5 phần hay 10 phần,… Trước đây mình cũng đã có câu hỏi tương tự như vậy và mãi cho đến khi đi làm, mình mới hiểu và có câu trả lời cho chủ đề này. Do đó, mình xin chia sẻ một chút kinh nghiệm của mình, cụ thể là về việc nên chia dữ liệu làm mấy phần và tại sao lại như vậy.
Tập Training, Validation & Testing
Trước hết, mình xin nhắc lại mục tiêu của việc xây dựng mô hình học máy là để có thể tìm ra mô hình có khả năng dự đoán tốt cho dữ liệu mới (unseen data). Trên thực tế, có rất nhiều thuật toán có thể được dùng để huấn luyện mô hình học máy, mỗi thuật toán lại có không ít các tham số có thể thay đổi. Để tìm ra mô hình tốt nhất, chúng ta thường phải đánh giá và so sánh chất lượng của nhiều (đôi khi là rất nhiều) mô hình khác nhau. Nói chung, thông thường chúng ta sẽ cần trả lời 2 câu hỏi:
- Câu hỏi 1 : Mô hình nào tốt nhất?
- Câu hỏi 2 : Độ chính xác của mô hình đó trên dữ liệu mới là bao nhiêu?
Để trả lời cho một trong hai câu hỏi nói trên thì một cách chia dữ liệu phổ biến là chia làm 2 phần: Training và Testing. Trong đó, tập Training được dùng để xây dựng hoặc huấn luyện mô hình, còn tập Testing được dùng để đánh giá xem mô hình đó có khả năng dự đoán tốt hay không.
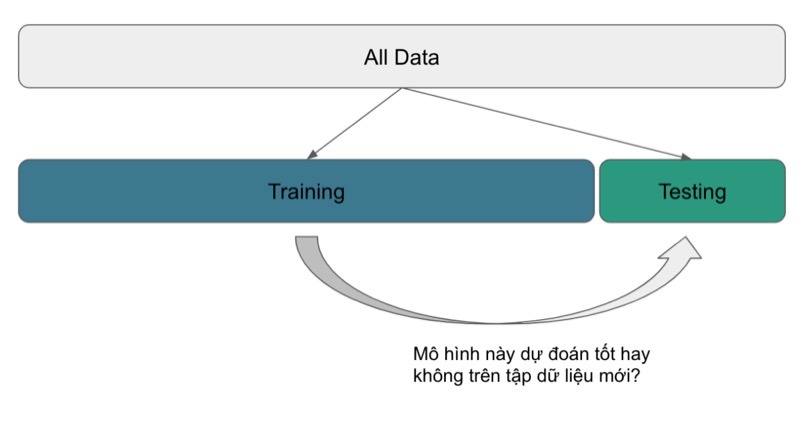
Một sai lầm thường gặp ở đây là dùng cách chia dữ liệu làm 2 phần để trả lời cho cả 2 câu hỏi nói trên. Tức là dùng tập Testing để làm tiêu chuẩn so sánh chất lượng, tinh chỉnh tham số và lựa chọn mô hình (câu hỏi 1) và rồi dùng luôn tập Testing để ước tính độ chính xác của mô hình trên tập dữ liệu mới (câu hỏi 2). Tuy nhiên, nếu như vậy thì thông tin từ tập dữ liệu Testing “vô tình” đã được sử dụng nhiều lần trong quá trình xây dựng mô hình, và tập Testing không còn là một mô phỏng tốt cho tập dữ liệu “mới” nữa. Nói một cách khác, câu trả lời cho câu hỏi số (2) sẽ không còn chính xác nữa.
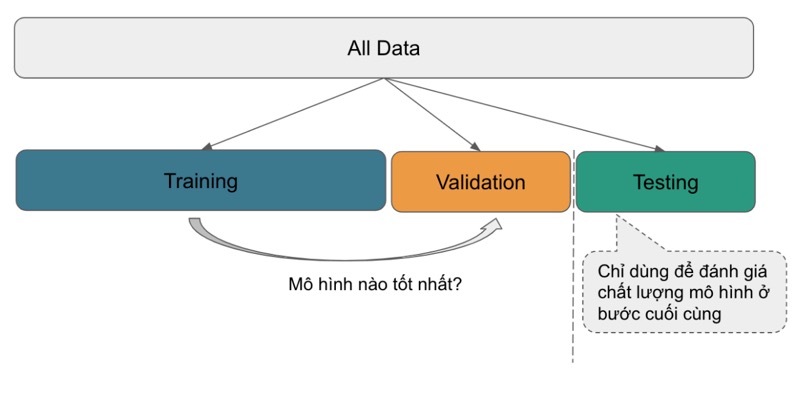
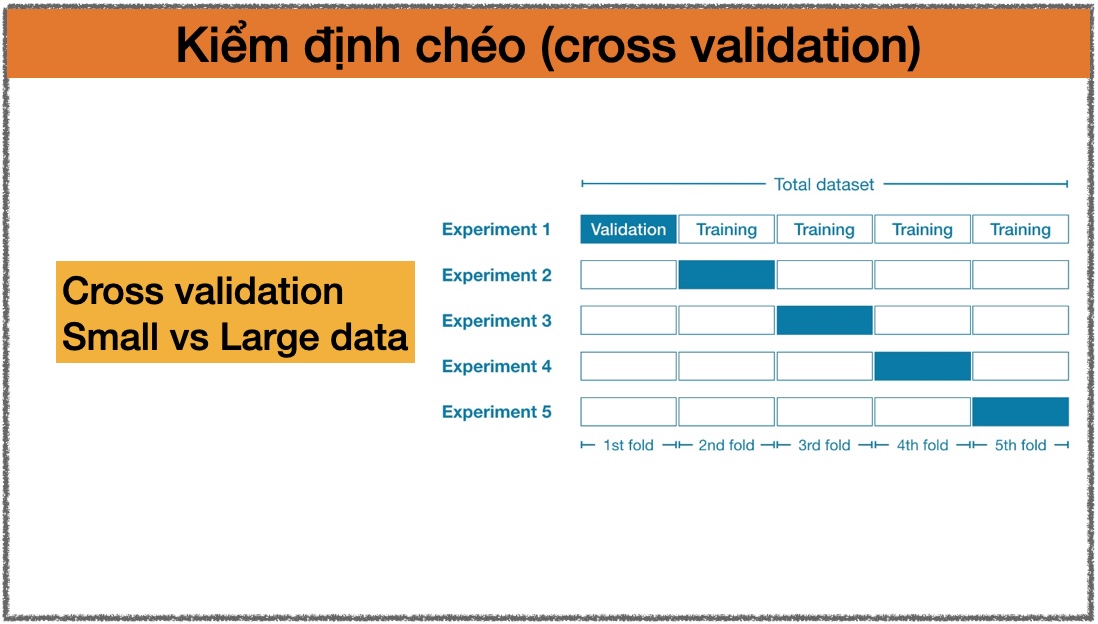
Để giải quyết vấn đề này, dữ liệu có thể được chia làm 3 phần: Training, Validation và Testing:
- Training được dùng để huấn luyện mô hình.
- Validation được dùng để đánh giá chất lượng, so sánh và lựa chọn những mô hình tốt nhất.
- Testing được dùng để đánh giá chất lượng mô hình ở bước cuối cùng.
Một vài điểm cần lưu ý
Một số cách gọi khác
Đôi khi các tập dữ liệu nói trên có những tên gọi khác, ví dụ như Validation còn được gọi là Development, Testing còn được gọi là Holdout. Các bạn nên xem mục đích sử dụng của các tập dữ liệu này là gì để tránh nhầm lẫn các khái niệm này với nhau.
Tỷ lệ chia dữ liệu
Thực ra không có một tỷ lệ nào được gọi là tốt nhất, nhưng thông thường thì tập Training sẽ chiếm phần nhiều nhất (để máy học được nhiều dữ liệu), tập Validation và Testing thì nhỏ hơn nhưng cũng không nên quá ít dữ liệu để đánh giá chất lượng mô hình một cách chính xác. Tỷ lệ Training – Validation – Testing hay được dùng nhất là 80 – 10 – 10, 60 – 20 – 20, 70 – 20 – 10,…
Cẩn thận với “sát thủ thời gian”

Thông thường, dữ liệu được chia một cách ngẫu nhiên. Tuy nhiên, chúng ta phải cẩn thận khi trong tập dữ liệu có ít nhất một cột là thời gian. Đặc biệt, khi cần dự đoán những sự kiện gắn liền với thời gian (ví dụ như dự báo thời tiết, dự đoán khả năng mua sản phẩm của khách hàng vào một ngày nhất định,…), chúng ta cần chia dữ liệu theo thời gian thay vì chia ngẫu nhiên.
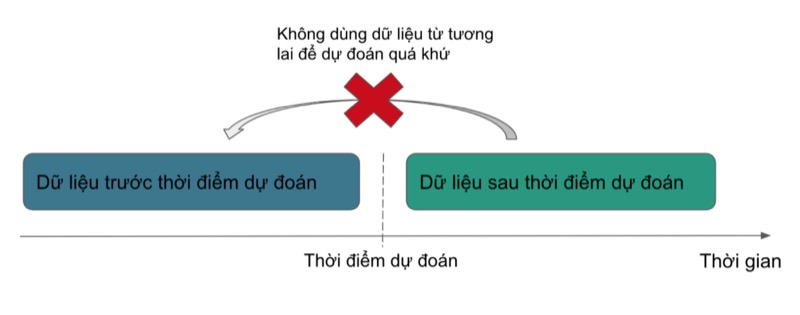
Trong trường hợp này, nếu chia dữ liệu một cách ngẫu nhiên, chúng ta có thể vô tình dùng dữ liệu tương lai để xây dựng mô hình và rồi đánh giá chất lượng bằng dữ liệu quá khứ, mô hình đó sẽ không chính xác cho việc dự đoán dữ liệu mới nữa.
Tạm kết
Tóm lại, trong thực tế dữ liệu cần được chia làm 3 phần trong quá trình xây dựng mô hình học máy. Trong đó, một phần nên được “cất đi”, chỉ được dùng để đánh giá chất lượng mô hình ở bước cuối cùng. Đây là cách chia để phục vụ 2 mục đích chính là lựa chọn mô hình tốt nhất và ước tính chất lượng của mô hình đó khi áp dụng lên dữ liệu mới.
Bên cạnh đó, cách chia dữ liệu cũng là một điểm cần lưu ý, đặc biệt là khi có yếu tố thời gian trong dữ liệu. Hãy cẩn thận, đừng để mô hình của bạn là nạn nhân của “sát thủ thời gian”.
Còn bạn thì sao? Bạn có kinh nghiệm gì thú vị về việc chia dữ liệu thì hãy chia sẻ để mọi người cùng học hỏi nha 🙂

Leave a comment